
前一个月看了《Effective C++》,边看边抄了份笔记,看完后感觉很过瘾,打算接着看《More Effective C++》,本来不打算写笔记了,但看到第一章就发现了值得记录的东西。不过这次我只记要点、结论,在此基础上按情况添加。毕竟笔记只是笔记,仅作复盘来用,原版内容仍然值得多读,尽管从导读部分就能感受到此书年代久远。
这本书的爸爸写它时,其兄弟《Effevtive C++》第三版还没出生,原文中有一些对其兄弟(第二版)内容的引用,形如 E1、E2,我在叙述时对其做了更新,指涉第三版中对应的条款。
一. 基础议题
01 仔细区别 pointers 和 references
使用 pointers 的时机:当你需要考虑 “不指向任何对象” 的可能性以及考虑 “在不同时间指向不同对象” 的能力时。前者,你可以将 pointer 设为 nullptr,后者是指针本来就有的特性。这两种情况,references 的性质(必须总代表某个对象,且无法更换)就决定了它都不适合。
使用 references 的时机:当你知道你需要指向某个东西(绝不存在不指向任何对象的情况),而且绝不会改变指向其他东西,或是当你实现一个操作符(operator [])而其语法需求无法由 pointers 达成。
这么来看,感觉 references 就像是 const 的 pointers(顶层 const ),好像其底层实现就是如此,至少在语言层面我们可以这么理解。
02 最好使用 C++ 转型操作符
static_cast 用来做一些基本的转型(其他转型操作符不干的活),int 转 double 之类的,比较常用来进行强制显式类型转换,不能用来做其他转型操作符的工作。
const_cast 只能改变对象的常量性,常用来转除掉某个对象的常量性。
dynamic_cast 用来执行继承体系中 “安全的向下转型或跨系转型动作”,也就是可以利用 dynamic_cast 将 “指向 base class objects 的 pointers 或 references ” 转型为 “指向 derived(或 sibling base) class objects 的 pointers 或 references”。转型失败会以一个 null 指针(当转型对象是指针)或一个 exception (当转型对象是 references)表现出来。
reinterpret_cast 的转换结果几乎总是与编译平台息息相关,因此不具备一致性。常用来转换 “函数指针” 类型,强迫编译器做一些转换。
03 绝对不要以多态(polymorphically)方式处理数组
多态的一个性质就是 base class 的指针(references)可以指向 derived classes 对象,且能进行动态绑定。指针的算术运算没有多态,指针的静态类型永远固定,数组对象几乎总是会设计指针的算术运算(array[i] 代表 *(array+i)),所以数组和多态不要混用。C++ 语言规范中说,通过 base class 指针删除一个由 derived classes objects 构成的数组,其结果未定义(调用的是指针静态类型的析构函数)。
04 非不要不提供 default constructor
凡可以 “合理从无到有生成对象” 的 classes,都应该内含 default constructors,而 “必须有某些外来信息才能生成对象” 的 classes,则不必拥有 default constructors 。但是当 class 缺乏 default constructor,其运行可能在 3 种情况下出现问题:1)产生数组时。2)不适用于许多 template-base container classes。3)在 E40 中说过,virtual base class constructors 的自变量必须由欲产生的对象的派生层次最深(most derived)的 class 提供。当 virtual base class 没有 default constructors,它的那些 most derived classes 将不得不知道、了解其意义,并提供 virtual base class 的 constructors 的实参。再一个但是,添加无意义的 default constructors,可能使 class 的默认初始化并非是正确的,因此不得不在成员函数中进行麻烦的正确性验证。确保 class constructors 将对象的所有字段都正确初始化,如果 default constructors 无法提供这种保证,那最好避免让它出现。当 classes 产出的对象被完全正确地初始化,实现上亦富有效率。
二. 操作符
05 对定制的 “类型转换函数” 保持警觉
两种函数允许编译器执行隐式类型转换:单实参 constructor 和隐式类型转换操作符。最好不要提供任何类型转换函数,在你从未打算也未预期的情况下,此类函数可能会被调用,而其结果可能是不正确、不直观的程序行为,很难调试。将 constructor 和类型转换运算符函数声明为 explicit,编译器便不能因隐式类型转换的需要而调用它们,不过显式类型转换仍是允许的。
编译器一次只能执行一个用户定义的类型转换(但是隐式的用户定义类型转换可以置于一个标准(内置)类型转换之前或之后,并与其一起使用)。利用这条规则,使用 proxy classes 技术,能够实现 explicit 的类似行为(C++11 以前的解决方案)。
如果在类类型和转换类型之间不存在明显的映射关系,则这样的类型转换可能具有误导性。此时,定义一个或多个普通的成员函数以从各种不同形式中提取所需的信息是一种更好的方案。例外情况是,定义向 bool 的类型转换是比较普遍的。注意,如果表达式被用作条件,则编译器会将显式的强制类型转换自动应用于它,即显式的类型转换将被隐式地执行。向 bool 的类型转换通常用在条件部分,因此 operator bool 一般定义成 explicit 的。
如果类中包含一个或多个类型转换,则必须确保在类类型和目标类型之间只存在唯一一种转换方式。否则的话,我们编写的代码将很可能会具有二义性。不要为两个类定义相同的类型转换,也不要在类中定义两个及以上转换源或转换目标是算术类型的转换。注意,如果我们对同一个类既提供了转换目标是算术类型的类型转换,也提供了重载的运算符,则将会遇到重载运算符与内置运算符的二义性问题。
总之,除了显式地向 bool 类型的转换之外,我们应该尽量避免定义类型转换函数,并尽可能地限制那些“显然正确”的非显式构造函数。
06 区别 increment/decrement 操作符的 前置(prefix)和后置(postfix)形式
重载函数以其参数类型来区分彼此,让后置式有一个 int 参数,并且在调用时,编译器默默地为该 int 指定一个 0 值,这仅是为了填平语言学上的漏洞,区分前置式和后置式而已。前置式返回一个 reference,后置式返回一个 const 对象。后置式返回一个 const 对象是为了避免形如 i++++ 这样的 ints 中不存在的行为。
后置式 increment 和 的 decrement 操作符的实现应以其前置兄弟为基础。不考虑前后置行为,单纯的 ++ 或 -- ,后置式的效率低于前置式,对于内置类型,编译器可以自动将后置式优化为前置式,对于用户自定义的类型,应尽可能使用前置式。
07 千万不要重载 && 、|| 和 , 操作符
对于这三个操作符,C++ 采用所谓的 “骤死式” 评估方式(短路求值)。很多程序依赖这种 “骤死式” 评估方式表现其正确行为。
当重载了这三个操作符时,“函数调用 语义” 会取代 “骤死式 语义”,使用操作符的表达式会被编译器视为调用重载操作符的函数,无论是 member function 还是 non-member function,当函数调用动作被执行,所有参数都必须评估完成,且 C++ 语言规范并未明确定义函数调用中各参数的评估顺序,因此,根本无法保证这三个操作符重载后的行为与它们内置版本的行为一样。
操作符重载的目的是要让程序更容易被阅读、被撰写、被理解,不是为了炫技。如果你没有什么好理由将某个操作符重载,就不要去做。
08 了解各种不同意义的 new 和 delete
此条款像是 E49~E52(第八章) 的导读,在看 E49~E52 之前需要了解的概念。
注:以下笔记大部分摘自《C++ Primer》,与《Effective C++》讲述的内容是一样的。
new operator 指的是 new expression(new 表达式),它执行三步操作:1)调用一个名为 operator new(或者 operator new[])的标准库函数,该函数分配一块足够大的、原始的、未命名的内存空间以便存储特定类型的对象(或者对象的数组)。2)编译器运行相应的构造函数以构造这些对象,并为其传入初始值。3)对像被分配了空间并构造完成,返回一个指向该对象的指针。
delete operator 执行两步操作:1)对指针所指的对象(或者指针所指的数组中的元素)执行对应的析构函数。2)编译器调用名为 operator delete(或者 operator delete[])的标准库函数释放内存空间。
标准库定义了 operator new 函数和 operator delete 函数的 8 个重载版本:
1
2
3
4
5
6
7
8
9
10
11
// 这些版本可能抛出异常
void *operator new(size_t); // 分配一个对象
void *operator new[](size_t); // 分配一个数组
void *operator delete(void*) noexcept; // 释放一个对象
void *operator delete[](void*) noexcept;// 释放一个数组
// 这些版本承诺不会抛出异常
void *operator new(size_t, nothrwo_t&) noexcept;
void *operator new[](size_t, nothrwo_t&) noexcept;
void *operator delete(void*, nothrwo_t&) noexcept;
void *operator delete[](void*, nothrwo_t&) noexcept;
这些函数并没有重载 new 表达式或 delete 表达式,不要被 operator 迷惑了,new 表达式和 delete 表达式的行为已经被语言固定死了(它们的行为总是如前面叙述的那样)。operator new 函数和 operator delete 函数的目的在于改变内存分配的方式。应用程序可以自定义上面函数版本中的任意一个,必须位于全局作用域或者类作用域中。
对于 operator new(或者 operator new[]) 函数来说,它的返回类型必须是 void*,第一个形参的类型必须是 size_t 且该形参不能含有默认实参,可以为它提供额外的形参,使用 new 的定位(placement)形式将实参传给新增的形参。这样的 operator new 被叫做 placement new,这个术语的另一层意思专指标准库的 placement new,该函数不分配任何内存,只是简单地返回指针实参,然后由 new 表达式负责在指定的地址初始化对象以完成整个工作。事实上,placement new 允许我们在一个特定的、预先分配的内存地址上构造对像,就像 allocator 的 construct 成员,且没有后者的诸多限制(传给 palcement new 的指针无须指向 operator new 分配的内存,甚至不需要指向动态内存)。
1
void *operator new(size_t, void*); // 不允许重新定义这个版本
对于 operator delete (或者 operator delete[])函数来说,它们的返回类型必须是 void,第一个形参类型必须是 void* 。当它们定义成类成员时,可以包含另外一个类型为 size_t 的形参,其初始值是第一个形参(void*)所指对象的字节数。如果基类有一个虚析构函数,则传递的这个字节数(size_t的形参)将因待删除指针(void*)所指对象的动态类型不同而有所区别,而且实际运行的 operator delete 函数版本也由对象的动态类型决定。
三. 异常
一份不很完全的 “exception-safe 软件” 设计指南。
09 利用 destructor 避免资源泄露
异常的引入,极有可能产生资源泄露,在异常处理中加入释放资源的步骤常常搞得程序乱七八糟。更好的方法 —— 以对象管理资源。尤其不要再用原始指针操控局部性资源。
10 在 constructors 内阻止资源泄露(resource leak)
constructors 是函数,同函数一样,抛出异常可能造成局部资源(class 成员保存的资源)的泄露,C++ 不会自动销毁 “仅部分构造完成” 的对象,更不会自动调用其析构函数。
在 constructors 内部增加异常处理步骤能够解决某些资源泄露问题,更好的办法是,class 内部的资源以对象管理,如果某次获取资源的过程中有异常抛出,此次资源还未获得更不会泄露一说,在此之前获取的资源由于通过对象管理,而成员对象会被自动销毁,它们获得的资源会在对应的析构函数中被释放。同时,你甚至不用再在 class 的析构函数中释放这些资源,因为管理资源的对象会自动释放。
尽管如此,constructor 还是应该尽可能不抛出异常。
11 禁止异常(exceptions)流出 destructors 之外
destructor 在两种情况下调用:1)当对象在正常状态下被销毁,也就是它离开了它的生成空间(scope)或是被明确地删除。2)当对象被 exception 处理机制 —— exception 传播过程中的 stack-unwinding(栈展开)机制 —— 销毁,通俗点说:当 exception 发生后,程序会找寻异常处理块,当前函数内未找到,异常会被抛出至函数调用端继续寻找,抛出异常则会引发所谓的栈展开,导致函数内的局部对象被销毁,从而调用到对象的析构函数。
destructors 绝不该抛出异常。理由如下:
1)如本节第一段所说的,exception 传播过程中的栈展开机制会导致 destructors 被调用,如果被调用的 destructor 抛出异常,控制权离开了 destructor,此时,正有另一个 exception 处于作用状态,C++ 会立刻调用 terminate 函数将程序结束掉。就算这个 destructor 在其内部的异常处理程序中完成了析构操作后才抛出的异常,也会造成栈展开过程中其后才销毁的对象未被销毁。
所以,全力阻止 exceptions 传出 destructors 之外。避免 terminate 函数在 exception 传播过程的栈展开机制中被调用,同时协助确保 destructors 完成其应该完成的所有事情。注意,不要在 destructors 中调用可能引发异常的函数。
12 了解 “抛出一个 exception” 与 “传递一个参数” 或 “调用一个虚函数” 之间的差异
函数参数的声明语法,和 catch 子句的声明语法,简直如出一辙。先看看 “抛出一个 exception” 发生了什么,自然也就明白它与后两者之间的差异。注意,当抛出一个 exception,控制权不会再回到抛出端。
被抛出作为 exception 的对象会被 exception 传播过程中的栈展开机制销毁。因此,一个对象被抛出作为 exception 时,总是会发生复制(copy),无论 catch 子句中进行捕捉 exception 的 “形参” 声明以何种方式传递(by value 或 by reference)。这个复制行为产生一个临时量,catch 子句捕捉的正是这个临时量。并且,这个复制行为是由对象的静态类型的 copy constructor 执行的。这意味着,抛出一个实际指向派生类对象的基类引用,实际抛出的却是一个基类 exception。下面的例子能够帮助理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Widget { ... };
class SpecialWidget: public Widget { ... };
void passAndThrowWidget()
{
SpecialWidget localSpecialWidget;
...
Widget& rw = localSpecialWidget;
throw rw; // 抛出一个类型为 Widget 的 exception
}
//.....................................................................
catch (Widget& w)
{
...
throw;
// 重新抛出当前的 exception,其间没有机会让你改变被传播的 exception 的类型。
// 如果 w 捕捉的是个 SpecialWidget 类型的 exception,抛出的也会是 SpecialWidget 类型,虽然 w 的静态类型是 Widget。
}
//.....................................................................
catch (Widget& w)
{
...
throw w; // 抛出一个新的 exception,
// 其类型总是 Widget —— w 的静态类型,
// 并且是 w 的一个副本。
}
前面提到,一个对象被抛出作为 exception 时,总是会发生复制(copy),复制行为产生一个临时量,catch 子句中捕捉的是该临时量,catch 子句中的 exception “形参” 声明指定了捕捉的方式:
1
2
3
catch (Widget w) ... // 以 by value 方式捕捉,意味着还得发生一次复制
catch (Widget& w) ... // 以 by reference 方式捕捉那个临时量,没问题
catch (const Widget& w) ... // 以 by reference 方式捕捉那个临时量,没问题
throw by pointer 实际上相当于 pass by pointer,两者(抛出和捕捉)传递指针副本,千万不要抛出一个指向局部对象的指针。
“exceptions 与 catch 子句相匹配” 的过程中,不会发生函数调用中的隐式类型转换,仅有两种转换可以发生:
- 1)“继承架构中的类转换”,一个针对 base class exception 而编写的 catch 子句,可以处理类型为 derived class 的exceptions。比如,C++ 标准程序库的 exception 继承体系。这种转换对于三种形式(by value、by reference、by pointer)都适用,同函数调用一样,by value 捕捉方式将造成对象切割问题。例如:
1
2
3
4
5
6
catch (Base) ... // 可捕捉的类型为 Base 和 Deriveds(被切割后的)
catch (Base&) ... // 可捕捉的类型为 Base 和 Deriveds(完整的)
catch (const Base&)... // 可捕捉的类型为 Base 和 Deriveds(完整的)
catch (Base*) // 可捕捉的类型为 Base* 和 Deriveds*
catch (const Base*) // 可捕捉的类型为 Base* 和 Deriveds*
- 2)从一个“有型指针”转为“无型指针”,所以一个对
const void*指针而设计的 catch 子句,可捕捉任何指针类型的 exception。
catch 子句总是依顺序做匹配尝试,即采用 “ first fit ”(最先吻合)策略,而不是 “ best fit ”(最佳吻合)策略,第一个匹配成功者便执行。所以,不要将 “针对 base class 而设计的 catch 子句” 放在 “针对 derived class 而设计的 catch 子句” 之前。
13 以 by reference 方式捕捉 exceptions
throw by pointer 是唯一在搬移 “异常相关信息” 时不需复制对象的一种做法(复制 pointer),但是程序员必须让 exception objects 在控制权离开那个 “抛出指针” 的函数之后依然存在。Global 对象、heap 对象以及 static 对象都没问题,但添加这种约束并不容易记住,catch 子句的作者还得面临 “to delete(heap 对象) or not to delete” 的问题。并且,标准异常处理机制抛出 exceptions 对象,而不是指针。
catch by value 可以消除上述 “exception 是否需要被删除” 及 “与标准 exception 不一致” 等问题。但是,除了当 exception objects 被抛出时发生一次复制外,捕捉时又发生了一次复制。并且还会引起对象的切割问题,derived class exception objects 被捕捉并被视为 base class exception ,失去其派生成分。当虚函数在其上被调用时,会被解析为 base class 的虚函数(和函数调用中的 by value 方式发生的事情一样)。
Catch-by-reference 不会有上面的问题。
明智运用 exception specifications
exception specifications (异常明细)明确指出一个函数可以抛出什么样的 exception,让代码容易被理解,但是它并不只是一个漂亮的注释。
如果函数抛出了一个并未列于其 exception specifications 的 exception,这个错误在运行时期被检验出来,特殊函数 unexpected 会被自动调用,unexpected 的默认行为是调用 terminate,terminate 的默认行为是调用 abort。是的,默认结果就是程序被中止。
很容易就让上面这种可怕的事情发生,编译器只会对 exception specifications 做局部性检验。C++ 允许,调用某个函数而该函数可能违反调用端函数本身的 exception specifications,尽管如此的调用行为可能导致程序被迫中止。
避免踏上 unexpected 之路的办法:
- 避免将 exception specifications 放在 “需要类型参数” 的 templates 身上。因为,templates 几乎必然会以某种方式使用其类型参数,无法预料类型参数的行为会抛出什么样的异常。
- 如果函数 B 没有 exception specifications,调用函数 B 的函数 A 也不要设定 exception specifications。
- 处理 “系统” 可能抛出的 exceptions。其中最常见的就是 bad_alloc(内存分配失败由 operator new 和 operator new[] 抛出),使用 new operator 时可能会遭遇它。哪怕我们对 “系统” 无比熟悉,“系统” 还是可能会抛出我们无法预料到的 exceptions。因此,预防很困难,治疗要简单 —— 直接处理非预期的 exceptions。C++ 允许你以不同类型的 exception 取代非预期的 exceptions,下面便是一种技术:
1
2
3
4
5
6
void convertUnexpected()
{
throw; // 重新抛出当前 exception
} // 也可抛出其他 exception
// 以 convertUnexpected 取代 unexpected
set_unexpected(convertUnexpected);
当函数抛出了一个并未列于其 exception specifications 的 exception,在运行时期被检验出来,unexpected 被 convertUnexpected 取代,后者被自动调用。非预期函数的替代者(convertUnexpected)重新抛出当前的 exception,该 exception 会被标准类型 bad_exception 取而代之。如果做了上述安排,并且每一个 exception specifications 都含有 bad_exception(或其基类 exception),任何非预期的 exception 抛出,都会被一个 bad_exception 取代。
当一个较高层次的调用者已经准备好要处理(使用 catch 捕捉)发生的 exception 时,可能 unexpected 函数却被调用了。因为,可能某个函数抛出了一个并未列于其 exception specifications 的 exception,从而导致 unexpected 函数被调用。阻止它的办法之一,将 unexpected 函数以上面的技术取而代之(抛出一个 exception,例如 bad_exception ,再使较高层次的调用者捕获)。
exception speficications 是一把双刃剑,在将它加入函数之前,请考虑它所带来的程序行为是否真是你所想要的。
15 了解异常处理(exception handing)的成本
一个 exception specification 通常会招致与 try 语句块相同的成本。不论 exception 处理过程需要多少成本,你都不应该付出比你该付出的部分更多。请将对 try 语句块和 exception specification 的使用限制于非用不可的地点,并且在真正异常的情况下才抛出 exception。
四. 效率
效率是件严肃的事情。有太多程序,其庞大的身躯和迟缓的脚步必须归咎于不良的设计和懒散草率的编程习惯。C++ 有可能对你原已存在的性能问题无能为力。如果你想写出一个高效的 C++ 程序,首先你必须能够写出一个高效程序。如果你所使用的高阶算法天生效率不彰,任何微调都影响不了大局。本章从 “和程序语言无关” 以及 “和C++本身有强烈关系” 这两个角度对 “效率” 发起攻击。这些都是战斗前的准备。
16 谨记 80-20 法则
17 考虑使用 lazy evaluation (缓式评估)
lazy evaluation(缓式评估):以某种方式撰写 classes,使它们延缓运算,直到那些运算结果刻不容缓地迫切需要为止。如果其运算结果一直不被需要,运算也就一直不执行。这可避免非必要的对象赋值,区别 operator[] 的读取和写动作,以及非必要的数据库读取动作和非必要的数值计算动作。
先实现一个 class,使用直接而易懂的 eager evaluation (急式评估)策略,但是在分析报告指出 “这个 class 乃性能瓶颈之所在” 后,以另一个实行 lazy evaluation 的 class 取代原先的 class。
18 分期摊还预期的计算成本
over-eager evaluation (超急评估) —— 做 “要求以外” 的更多工作,再被要求之前就先把事情做下去。两种做法:
- caching —— 将 “已经计算好而有可能再被需要” 的数值保留下来,比如 min、max、avg 这一类数值。
- prefecting —— 预先取出(或分配),一次读取大块数据比分成两三次每次读取小块数据,速度上快得多。如果某处的数据被需要,通常其邻近的数据也会被需要 —— 有名的 locality of reference 现象。“系统调用” 往往比 “进程(process)内的函数调用”速度慢,所以应尽可能不要采用系统调用。
以上的做法,皆印证了:较佳的做法往往导致较大的内存成本,空间可以交换时间。但是,少数情况下,对象变大会降低软件的性能,因为换页活动活动会增加,缓存击中率(cache hit rate)会降低,利用分析器找出这类问题的症结所在。
over-eager evaluation 和 lazy evaluation 并不矛盾。当你必须支持某些运算而其结果并不总是需要的时候,后者可以改善程序效率;当你必须支持某些运算而其结果几乎总是被需要,或其结果多次被需要的时候,前者可以改善程序效率。
19 了解临时对象的来源
C++ 真正的所谓临时变量是不可见的 —— 不会在你的源代码中出现。只要产生一个 non-heap object 而没有为它命名,便诞生了一个临时对象。这通常发生于两种情况:
- 当隐式类型转换被施行起来以求函数调用能够成功。为了让函数调用成功,需产生临时对象,发生于 “传递对象给一个函数,而其类型与它即将绑定上去的参数类型不同” 的时候。只有当对象以 by value 或 by reference-to-const 方式传递时,这类转换才会发生。考虑有一个 reference-to-const 形参的函数,当类型不吻合的状态消除,函数调用才会成功,编译器产生一个形参类型的临时对象,以实参调用该形参类型的 constructor。于是,这个 reference-to-const 的参数被绑定于这个临时对象上。当函数返回,此临时对象会被自动销毁。by reference-to-non-const 参数不会发生此类转换,C++ 语言禁止为 non-const reference 参数产生临时对象,non-const 意味着可变,变化作用于临时对象,而不是真正传递的那个实参,这不是程序员所企盼的结果。reference-to-const 参数则不需要承担此问题。两个做法可以消除此种转换,一是重新设计代码,使这类转换不会发生(条款5),二是修改软件,使这类转换不再需要(条款21)。
- 当函数返回对象的时候 —— 返回值的构造和析构。条款 20 介绍所谓的 “返回值优化(return value optimization)”。
临时对象很耗成本,所以应该尽可能消除它们。
20 协助完成 “返回值优化 (RVO)”
有些函数必须返回对象,无法消除。从效率的眼光看,不应该在乎函数返回了一个对昂,应该在乎的是那个对象的成本几何。
返回所谓的 constructor arguments,特殊的优化行为,利用函数的 return 点消除一个局部临时对象(并可能用函数调用端的某对象取代),它的专属名称 —— return value optimization。脚注中说,命名对象和匿名对象都可以借由 return value optimization 被优化去除,也就是说,返回一个对象的行为如今总是会被编译器优化。
21 利用重载技术(overload)避免隐式类型转换(implicit type conversions)
对于 operator+ 这样的非成员函数,隐式类型转换,使得不同类型之间的混合运算成为可能。之所以能成功,是因为类型转换产生了临时对象。通过重载函数 operator+ 也可以实现相同的目的,声明数个 operator+ 函数,每个函数有不同的参数表。这一做法,消除了类型转换的需求,也就避免了临时对象的成本。不过需要注意,每个 “重载操作符” 必须获得至少一个 “用户定制类型” 的参数。
也不要忘了 80-20 法则,增加一大堆函数不见得是件好事。除非你有好的理由相信,使用重载函数后,程序的整体效率可获得重大改善。
22 考虑以操作符复合形式(op=)取代其独身形式(op)
要确保操作符的复合形式和其独身形式之间的自然关系能够存在,一个好方法就是以前者为基础实现后者(条款6)。
操作符的复合版本比其对应的独身版本有着更高效率的倾向。身为一位程序库设计者,应该两者都提供,以便允许你的客户在效率(op=)与便利性(op)之间做取舍;身为一位应用软件开发者,如果性能是重要因素的话,应该考虑以 “复合版本” 操作符取代其 “独身版本” 。
自古以来匿名对象总是比命名对象更容易消除,所以面对临时对象与命名对象的抉择时,最好选择临时对象(尤其在搭配旧式编译器时)。
23 考虑使用其他程序库
不同的程序库即使提供相似的机能,则往往表现出不同的性能取舍策略,所以,一旦你找出程序的瓶颈,你应该思考是否有可能因为改用另一个程序库而移除了那些瓶颈。这是由于不同的程序库将效率、扩充性、移植性、类型安全性等的不同设计具现化。
完全依赖性能评估软件是很愚蠢的行为,但完全忽略它也一样愚蠢。
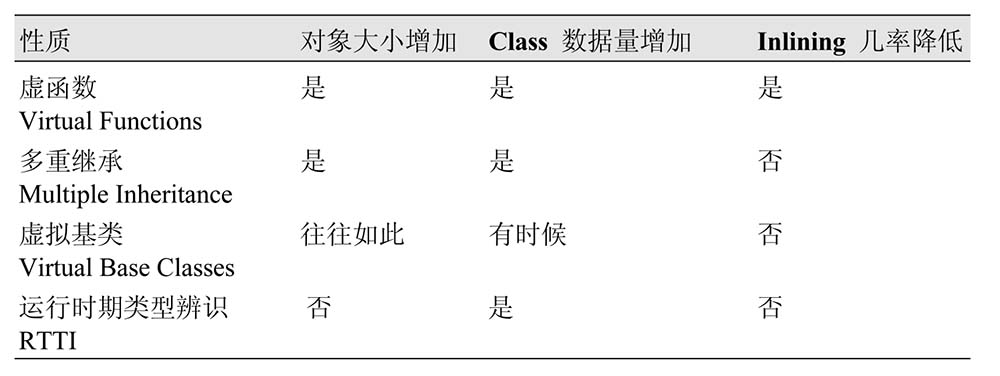
24 了解 virtual function、multiple inheritance、virtual base classes、runtime type identification 的成本
编译器使用所谓的 vtbls (virtual tables) 和 vptrs (virtual table pointers)实现虚函数。它们是实现虚函数的主要成本。
vtbl 是一个由 “函数指针” 架构而成的数组(或链表)。凡声明(或继承)虚函数的 class,都有自己的一个 vtbl,其中的条目就是该 class 的各个虚函数实现体的指针。vtbr 保存的只有 class 自身的虚函数指针,包括 class 自身声明以及继承的虚函数,若继承而来的虚函数被 override ,vtbt 中保存的是当前 class 的函数版本(ovrride 后的)。
因此,必须为每个拥有虚函数的 class 耗费一个 vtbl 空间,其大小视虚函数的个数(包括继承而来的)而定。程序中的每一个 class 的 vtbl 只需一份就好,编译器的暴力做法是,在每一个需要 vtbl 的目标文件都产生一个 vtbl 副本,最后再由连接器剥除重复的副本,使最终可执行文件或程序库内,只留下每个 vtbl 的单一实体。编译器的勘探式做法是,class’s vtbl 被产生于 “内含其第一个 non-inline,non-pure 虚函数定义式” 的目标文件中。对于勘探式做法,将虚函数声明为 inline 会有麻烦,这会导致编译器在每一个 “使用了 class’s vtbl” 的目标文件产生一个 vtbl 复制品。目前的编译器通常都会忽略虚函数的 inline 指示。
声明有虚函数的 class 有一个 vtbl,声明有虚函数的 class 的对象都含有一个隐藏的 data member —— vptr —— 用来指向该 class 的 vtbl。它被编译器加入某个唯编译器才知道的位置。因此,每一个拥有虚函数的对象内,都必须付出 “一个额外指针” 的代价。注意,较大的对象意味着较难塞入一个缓存分页(cache page)或虚内存分页(virtual memory page)之中,也就意味着你的换页(paging)活动可能会增加。
程序中含有虚函数调用动作时,编译器不知道调用的函数具体是哪一个(视运行时调用对象而定),但是编译器仍然必须为这些调用动作产生可执行代码,而且必须确保正确的函数被调用:
- 根据对象的 vptr 找出其 vtbl。
- 找出被调用函数在 vtbl 内的对应指针。每个虚函数都有一个独一无二的表格索引。
- 调用上一步所得指针指向的函数。
一个这样的语句:pC1->f1(); ,产生出这样的代码: (*pC1->vptr[i])(pC1);。因此,调用一个虚函数的成本,基本上和 “通过一个函数指针来调用函数” 相同,虚函数本身并不构成性能上的瓶颈。
虚函数的第三个成本:你事实上放弃了 inlining(不考虑虚函数通过对象调用,这可被 inlined,但大部分虚函数调用动作是通过对象的指针或 reference 完成的,这才是常态)。“virtual” 意味 “等待,直到运行时才知道哪个函数被调用”,而 “inline” 意味 “在编译器,将调用端的调用动作被调用函数的函数本体取代”,编译器面对某个调用动作,却无法知道哪个函数该被调用,也就没能力将该函数调用 inlining 了。
多重继承会让事情更复杂,一个对象之内会有多个 vptrs(每个 base class 各对应一个)。
多重继承往往导致 virtual base classes(虚拟基类)的需求(这儿说的是 virtual 继承),virtual base classes(virtual 继承) 的实现做法常常利用指针,指向 “virtual base class 成分”,以消除复制行为,而你的对象内可能出现一个(或多个)这样的指针。举个例子:
1
2
3
4
class A { ... };
class B: virtual public A { ... };
class C: virtual public A { ... };
class D: public B, public A { ... };
D对象的内存布局可能看起来如下:
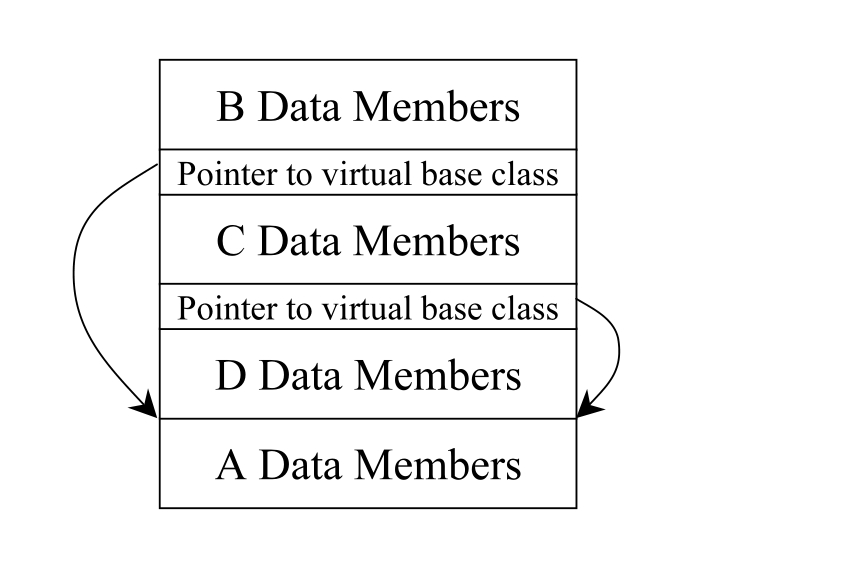
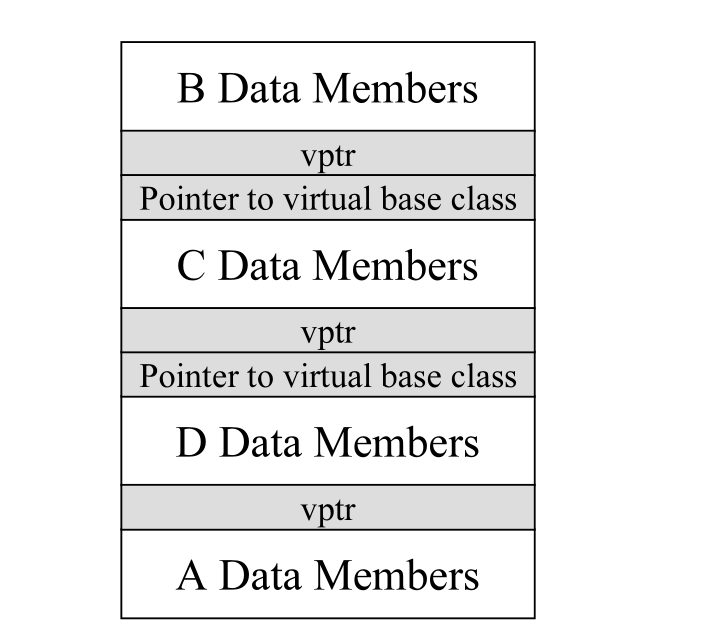
运行时期类型辨识(runtime type identification, RTTI) 让我们得以在运行时期获得 objects 和 classes 的相关信息,这些信息被存放在类型为 type_info 的对象内。可以利用 typeid 操作符取得某个 class 相应的 type_info 对象。C++ 规范说,只有当某种类型拥有至少一个虚函数,才能保证我们能够检验该类型对象的动态类型。这听起来有点像 vtbl。而 RTTI 的设计理念就是,根据 class 的 vtbl 来实现。例如:
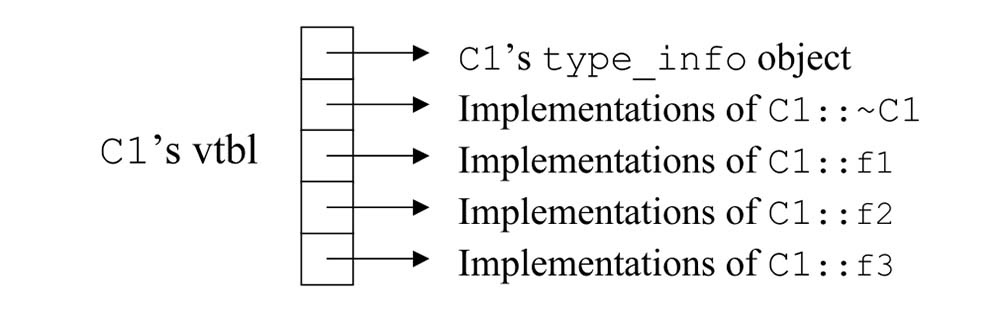
如此一来,RTTI 的成本只需每一个 class vtbl 内增加一个条目,再加上每个 class 所需的一份 type_info 对象空间。
下面是一份总结:
五. 技术
这一章的每个条款各讲述一种技术,各条款之间按顺序相辅相成。
这一章挺有难度的,就只记录标题,标题概述了每个条款可以解决的问题,如果日后需要一份锦囊妙计,回来找找再去翻书。