
《Effecive Modern C++》(中文版)阅读笔记的风格同《More Effective C++》。以我自己的情况进行记录,并将个别术语换成了我理解的偏大陆词汇,比如,将型别换为类型。不过在看习惯之后,我发现型别这个词也挺不错的。
Chapter 1. Deducing Types
Item 1: Understand template type deduction
函数模板的类型推导中,编译器通过 expr 推导两个类型:T 和 ParamType,ParamType 常包含一些饰词,如 const 或引用符号等限定词。
1
2
3
4
template<typename T>
void f(ParamType param);
// 调用
f(expr);
- 当
ParamType是指针(T*、const T*)或引用(T&、const T&),类型推导会忽略expr的引用(如果有的话),然后对expr的类型和ParamType执行模式匹配,得出T。 - 当
ParamType是个万能引用(T&&),左值的expr推导出T和ParamType都为左值引用,param的类型也是左值引用。右值的expr同前一种情况,执行模式匹配。 ParamType非指针和引用(T、const T),就是所谓的按值传递。param将是一个expr的副本,expr的引用属性、顶层 const 属性和 volatile 属性都会被忽略,底层 const 属性会被保留进推导中。例如,若expr的类型是const char* const(指向const char的const指针),ParamType为T和const T都推导出的T为const char*(指向const char的指针)。
当数组和函数作为实参时,按值传递(ParamType 为 T),数组为实参会推导 T 为指向数组内部元素的指针,函数为实参会推导 T 为函数指针。按引用传递(ParamType 为 T&),数组为实参会推导 T 为数组类型(包含数组大小),函数为实参会推导 T 为函数类型。注意,后一种情况推导出的 T 并不是 param 的类型 ParamType,还要加上 &(即数组引用和函数引用) 。
Item 2: Understand auto type deduction
auto 类型推导就是模板类型推导。当某变量采用 auto 来声明时,auto 就扮演了模板中的 T 这个角色,而变量的类型修饰符则扮演的是 ParamType 的角色。从概念上来说,auto 类型推导相当于编译器仿佛对应于每个 auto 声明,生成了一个模板和一次使用对应的初始化表达式针对该模板的调用。所有的情况都一模一样,在 auto i 、const auto i 、const auto& i 中,auto 相当于 T ,i 前面的整个声明相当于 ParamType。
不过,有一个例外。auto 类型推导会假定用大括号括起的初始化表达式代表一个 std::initializer_list,即在表达式 auto x = {11, 23, 9}; 中,auto 类型推导得到 x 的类型是 std::initializer_list<int>。模板类型推导不会这么做,如果可以的话,编译器既要从初始值 {11,23,9} 中推导出 std::initializer_list<T> 中的 T为 int ,还要推导出模板中的 T 为 std::initializer_list,编译器才不会这么自作多情,但它却对 auto 情有独钟,在 auto 推导中先推导出 std::initializer_list<T> 中的 T ,然后再推导 auto 。为什么这样?作者说他也感到奇怪并且找不到一个有说服力的解释,但规则就是规则。记住这条规则。也记住,auto 推导和模板型别推导的类似只是概念上的类似,而不是具体的实现手法。
特别注意,C++14 允许使用 auto 说明函数的返回类型需要推导,同时允许在 lambda 的形参声明中用到 auto 来实现 lambda 参数类型的自动推导。这些 auto 用法使用模板类型推导,而不是 auto 类型推导,要注意前面所说的两者的不同之处。
Item 3: Understand decltype
decltype —— declared type —— 得出名字的声明类型。即, decltype 会得出变量或表达式的类型而不作任何修改,注意与 auto 的不同,decltype 会保留引用和顶层 const 属性。不过,如果是比仅有名字更复杂的左值表达式,即一个左值表达式不仅是一个型别为 T 的名字,decltype 保证得出的类型总是左值引用。例如,一个 T 类型的变量 x(x 是左值),单纯的名字 x 得出 T,特殊的 (x) 也是左值,却会得出 T&。不过,绝大多数左值表达式都自带一个左值引用饰词。
C++14 的 decltype(auto) 相当于遵循 auto的用法却以 decltype 的规则从初始化表达式推导出变量的类型。条款 2 提到 auto 使用模板类型推导规则,decltype(auto) 使用 decltype 的规则从初始化表达式中推导类型。
auto 和 decltype 在《 C++ Primer 》中的描述。下面这个例子来自书上:
1
2
3
4
5
6
7
tempalte<typename Container, typename Index>
decltype(auto)
authAndAccess(Container&& c, Index i)
{
authenticateUser();
return std::forward<Container>(c)[i];
}
c 的声明是个万能引用,decltype(auto) 确保了函数的返回类型与 Container 的 [] 返回类型保持一致。无论 Container 的 [] 返回引用或值,都没问题。
Item 4: Know how to view deduced types
撰写代码阶段通过 IDE 编辑器(鼠标指针悬停等方式)可显示出某个程序实体的类型。这是因为,IDE 让 C++ 编译器(或至少也是其前端)在 IDE 内执行一轮。
在编译阶段,使用想要显示的类型导致编译错误,该类型就会被报告错误的消息显示出。例如,以该类型具现一个仅有声明没有定义的类模板。
运行时阶段,通过 typeid 和 std::typeinfo::name 显示类型信息会依编译器的不同产生不同的非人类可读的结果,并且标准规格上说,std::type_info::name 处理类型的方式就仿佛是向函数模板按值传递形参一样,因此,引用、const 等饰词将被忽略或移除。Boost 的 TypeIndex 库虽然可以胜任这份工作,但理解 C++ 型别推导规则也是必要的。
Chapter 2. auto
Item 5: Prefer auto to explicit type declarations
auto 避免了潜在的未初始化风险,因为 auto 通过初始化物推导变量类型。auto 可用于声明 lambda 表达式,在 C++14 中,lambda 表达式的形参中也可以使用 auto。并且,使用 auto 声明的、存储着一个闭包的变量和该闭包是同一类型,从而它要求的内存量也和该闭包一样。而使用 std::function 声明的、存储着一个闭包的变量是 std::function 的一个实例,一般都会比 auto 声明的变量使用更多内存,且调用闭包的行为也来得慢。
显式指定类型可能导致既不想要,也没想到的隐式类型转换。除非,你无时无刻都明确了解初始化物与声明中显式指定的类型相容或有正确的转换关系。使用 auto,无需担心声明变量的类型和它的初始化表达式的类型之间的不匹配等问题。
auto 会带来源代码可读性问题吗?这依每个人的专业判断而不同。在其他语言中,auto 已不是什么新鲜事。软件开发社区已经积累了丰富的类型推导方面的经验,而这也说明此类技术并不会与撰写和维护大型的、工业强度的基础代码这样的工作产生冲突。在很多情况下,对于对象类型的抽象理解与了解它的精确类型同等有用,例如容器、计数器、智能指针,别忘了再取个好一点的变量名字。
auto 随其初始化表达式的类型变化而自动随之改变,这意味着一些重构动作被顺手做掉了。
Item 6: Use the explicitly typed initializer idiom when auto deduces undesired types
标准库很多地方使用了代理类的设计:模拟或增广其他类型的类。代理类往往隐藏在背后,客户使用代理类如同使用代理类所代理的那个类型一般。“隐形”代理类和 auto 无法和平共处。代理类的对象往往会设计成仅仅维持到到单个语句之内,所以,无意中使用 auto 创建这种类的变量,往往就是违反了基本的库设计的假定前提。例如,在一个 + 与 = 的赋值语句中(Matrix sum = m1 + m2 + m3;),代理类在 + 操作中生产出来,在 = 操作中被隐式地当作代理的那个类型被赋值过去,语句结束代理类就被销毁。把 Matrix 换成 auto 得到的 sum 将是一个代理类对象,其内部可能并没有真正的值。
如何发现问题(代理类)?
- 使用代理类的库往往会在其文档中写明这一点。
- 代理类大多数是由客户意欲调用的函数所返回的,函数签名往往会反应出它们的存在。例如,特化的
std::vector<bool>的[]返回一个其内部定义std::vector<bool>::referenc模拟bool。 - 仔细观察你所使用的接口。
如何解决问题(用 or 不用 auto)?只要问题出在 auto 被决断成了代理类型,而非意欲代理的那个类型,解决方案都不必放弃 auto。auto 本身并不是问题,问题在于 auto 没有推导你想推导出的类型。解决方法应该是强制进行另一次类型转换 —— 带显式类型的初始化物习惯用法(the explicitly typed initializer idiom)。即,auto sum = static_cast<Matrix>(m1 + m2 + m2);。这种习惯用法同样可以应用于想要强调意在创建一个类型有异于初始化表达式类型的变量的场合,让事情变得显而易见:
1
2
3
// d 是一个 double
int index = d * c.size(); // 强制转换的事实含含糊糊
auto index = static_cast<int>(d * c.size()); // 显而易见的做法
Chapter 3. Moving to Modern C++
Item 7: Distinguish between () and {} when creating objects
C++11 引入了统一初始化:单一的、至少从概念上可以用于一切场合、表达一切意思的初始化 —— 大括号初始化(braced initialization)。
大括号初始化的新特性:
- 直接指定一个 STL 容器在创建时持有一个特性集合的值。
- 为非静态成员指定默认初始化值可以使用大括号和 “=” 的初始化语法,却不能使用小括号。
- 不可复制对象(如
std::atomic型别的对象),可以采用大括号和小括号来进行初始化,却不能使用 “=”。注:前三条揭露出大括号初始化的 “统一” 之名。 - 禁止内建型别之间进行隐式窄化型别转换(narrowing conversion)。
- C++ 规定:任何能够解析为声明的都要解析为声明,而这会带来副作用,一个令人苦恼的解析语法,程序员本想以默认方式构造一个对象,结果却一不小心声明了一个函数。例如,这个语句
Widget w2();声明了一个名为w2、返回一个Widget型别对象的函数!由于函数声明不能使用大括号来指定形参列表,所以使用括号来完成对象的默认初始化没有上面这个问题:Widget w3();。
大括号初始化的缺陷,源于大括号初始化物、std::initializer_list 以及构造函数重载决议之间的纠结关系:
- Item 2 曾说过:使用大括号初始化物来初始化一个使用使用
auto声明的变量,推导出来的型别会是std::initializer_list。 - 如果有一个或多个构造函数声明了任何一个具备 std::initializer_list 型别的形参,采用大括号初始化语法的调用语句会强烈地优先选用 std::initializer_list 型别形参的重载版本,哪怕是复制或移动的构造函数也是如此。换句话说,大括号初始化语法优先选用带有 std::initializer_list 型别形参的构造函数(即使其他重载版本有着貌似更加匹配的形参表),只有在找不到任何办法把大括号初始化物中的实参转换成 std::initializer_list 模板中的型别时,编译器才会退而去检查其他普通的重载决议。
- 空大括号对表示的是 “没有实参”,而非 “空的 std::initializer_list”。即,一对空大括号初始化对象执行的是默认构造,而非以一个不含任何元素的 std::initializer_list 为基础执行构造。
作为一个类的作者,需要有清醒的意识,了解自己撰写的一组重载构造函数中只要有一个或多个声明了任何一个具备 std::initializer_list 型别的形参,则使用可大括号初始化的客户代码可能会只发现那些具备 std::initializer_list 型别形参的重载版本。最好把构造函数设计成客户无论使用小括号还是大括号都不会影响调用的重载版本,因此,std::vector 的接口设计被视为败笔(作者在书中如此说道)。
往一组重载函数中添加带有 std::initializer_list 型别形参的新版本构造函数时,可能使别的重载版本连露脸的机会都没有。在添加这样的重载版本时,一定要做到心中完全有数。
作为开发类客户代码的程序员,创建对象时选用一对小括号还是大括号可要三思而后行。默认选用大括号的程序员是被其宽泛的应用语境、对隐式窄化型别转换的禁止,以及对最令人苦恼之解析语法的免疫所吸引。小括号的拥护者则可以免受 auto 型别推导意外错误之苦,在创建对象时也不会碰到带有 std::initializer_list 型别形参的构造函数设置的路障,但有些场合非用大括号不可。究竟选用哪一方更好,作者的建议是选用任一方并坚持下去。
作为开发模板的程序员,在模板内部进行对象创建时,到底应该使用小括号还是大括号会成为一个棘手问题。这是因为,在模板内部创建对象时并不知道对象的型别(对象的型别由使用者在具现化模板时指定的嘛),自然也就不知道该型别的大括号和小括号表达些什么。使用大括号还是小括号,模板的作者不可能下这个判断,只有调用者才有决定权。标准库函数 std::make_unique 和 std::make_shared 就面临这样的问题,解决办法是在内部使用了小括号,并把这个决定以文档的形式广而告之,作为其接口的组成部分。书中注释中说,更弹性的设计,也就是允许调用者自行决定在从模板中生成的函数内使用小括号还是大括号的设计,是可以实现的。参阅这里。
Item 8: Prefer nullptr to 0 and NULL
0 和 NULL 都不具备指针型别。字面常量 0 的型别是 int,而标准允许各个实现给予 NULL 非 int 的整形型别(如 long)。nullptr 不具备整形型别,也不具备指针型别,但可以把它想成一种任意型别的指针。nullptr 的实际型别是 std::nullptr_t,并且在一个漂亮的循环定义下,std::nullptr_t 的定义被指定为 nullptr 的型别。型别 std::nullptr_t 可以隐式转换到所有的裸指针型别,这就是为何 nullptr 可以扮演所有型别指针的原因。
模板型别推导会将 0 和 NULL 推导成“错误”型别(即他们的真实型别,而给退而求其次的表示空指针这个意义),这个事实构成了应该在表示空指针时使用 nullptr 而非 0 或 NULL 的压倒性理由。同时,nullptr 不会造成 0 和 NULL 稍不留意就会遭遇的重载决议问题。不过,还是不要在指针型别和整形之间做重载,有些程序员还是会继续使用 0 和 NULL。
Item 9: Prefer alias declarations to typedefs
除了 typedef ,C++11 提供了别名声明(alias declaration):
1
2
using UptrMapSS =
std::unique_ptr<std::unordered_map<std::string, std::string>>;
别名声明除了在处理涉及函数指针的型别时,比较容易理解之外,还可以模板化(这种情况下它们被称为别名模板,alias template)。typedef 就不支持,程序员不得不用嵌套在模板化的 struct 里的 typedef 才能硬搞出这种机制。
1
2
3
4
5
6
7
8
9
10
11
template<typename T>
using MyAllocList = std::list<T, MyAlloc<T>>;
MyAllocList<Widget> lw;
template<typename T>
struct MyAllocList {
typedef std::list<T, MyAlloc<T>> type;
};
MyAllocList<Widget>::type lw;
比如,C++11 中的型别特征就是用嵌套在模板化的 struct 里的 typedef 实现的。型别特征是在头文件 <type_traits> 给出的一整套模板,对给定待变换型别T,其结果型别为 std::transformation<T>::type ,这些变换的应用都以 “::type” 结尾,将它们应用于模板内的型别形参时,每次都要在前面加上 typename 。到了 C++14,C++11 中的所有型别变换都加上了对应的别名模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
std::remove_const<T>::type // C++11: const T -> T
std::remove_const_t<T> // C++14 中的等价物
std::remove_reference<T>::type // C++11: T&/T&& -> T
std::remove_reference_t<T> // C++14 中的等价物
std::add_lvalue_reference<T>::type // C++11: T -> T&
std::add_lvalue_reference_t<T> // C++14 中的等价物
// C++ 14 标准
template <class T>
using remove_const_t = typename remove_const<T>::type;
template <class T>
using remove_reference_t = typename remove_reference<T>::type;
template<class T>
using add_lvalue_reference_t =
typename add_lvalue_reference<T>::type;
Item 10: Prefer scoped enums to unscoped enums
不限范围的(unscoped)枚举型别:C++98 风格的枚举型别中定义的枚举量的名字会泄露到枚举型别所在的作用域。它们在 C++11 中的对等物,限定作用域的(scoped)枚举型别则不会以泄露名字,限定作用域的枚举型别通过 enum class 声明,因此也被称为枚举类。
1
2
3
enum Color {black, white, red}; // black,white,red 所在作用域
// 和 Color 相同
auto white = false; // 错误!white 已在范围内被声明过了
1
2
3
4
5
enum class Color {black, white, red}; // black,white,red 所在作用域
// 被限定在 Color 内
auto white = false; // 没问题,范围内并无其他 “white”
Color c = white; // 错误!范围内并无名为“white”的枚举量
auto c = Color::white; // 没问题
限定作用域的枚举型别的枚举量是更强型别的(strongly typed),从限定作用域的枚举型别到任何其他型别都不存在隐式转换路径(强型别转换能够实施),而不限范围的枚举型别中的枚举量可以隐式转换到整数型别(并能够从此处进一步转换到浮点型别)。
限定作用域的枚举型别可以进行前置声明,即其型别名字可以比其中的枚举量先声明。限定作用域的枚举型别的底层型别是已知的(默认是 int),而对于不限范围的枚举型别,为了使编译器在枚举型别使用前确认其底层型别选择哪一种,C++98 就只提供了枚举型别定义(即列出所有枚举量)的支持,枚举型别声明则不允许。对于不限范围和限定作用域的枚举型别,都可以指定其底层型别,这样做了后,不限范围的枚举型别也能够进行前置声明了:
1
2
enum Color: std::uint8_t; // 不限范围的枚举型别的前置声明
// 底层型别是 std::unit8_t
当需要引用 C++11 中的 std::tuple 型别的各个域时,不限范围的枚举型别还是有用的。关于如何以这两种枚举型别引用 std::tuple 型别的各个域的细节,详见书上。
Item 11: Prefer deleted functions to private undefined ones
优先选用删除函数,而非 private 未定义函数。后者无法应用于类外部的函数,也不总是能够应用于类内部的函数(能应用也可能直到链接阶段才发挥作用)。而任何函数都可以删除,包括非成员函数(为函数调用中想要滤掉的型别创建删除重载版本)和模板具现(删除函数可以阻止那些不应该进行的模板具现)。
习惯上,删除函数会被声明为 public,而非 private,这是因为当客户代码尝试使用某个成员函数时,C++ 会优先检验可访问性,后校验删除状态。当客户代码试图调用某个 private 删除函数时,有些编译器只会抱怨该函数为 private,尽管函数的可访问性并不影响其是否可用。
Item 12: Declare overrding functions override
“改写”(override)和“重载”(overload)读起来很像,却是两个毫不相关的概念。由于对于声明派生类中的改写,保证正确性很重要,而出错又很容易,C++11 提供了一种方法来显式地标明派生类中的函数是为了改写基类版本:为其加上 override 声明。无论何时,只要你在派生类中声明了一个函数,并且该函数意在改写基类中的一个虚函数,请确保你给该函数加上 override 声明。
Item 13: Prefer const_iterators to iterators
const_iterator 是 STL 中相当于指涉到 const 的指针的等价物,它们指涉到不可被修改的值,任何时候只要需要一个迭代器而其至涉到的内容没有修改必要,就应该使用 const_iterator。并不存在 const_iterator 到 iterator 的型别转换。
C++11 仅添加了非成员函数版本的 begin 和 end。下面是非成员函数版本的 cbegin 的一个实现:
1
2
3
4
5
template <class C>
auto cbegin(const C& container)->decltype(std::begin(container))
{
return std::begin(container);
}
这个 cbegin 模板接受一个形参 C ,实参型别可以是任何表示类似容器的数据结构,并通过其引用到 const 型别的形参 container 来访问该实参。调用非成员函数版本的 begin 函数并传入一个 const 容器会产生一个 const_iterator,而模板返回的正是这个迭代器。这样一来,这个非成员函数版本的 cbegin 也可用在那些仅支持 begin 的容器上了。该模板对内建数组同样适用,因为 C++11 的非成员函数版本的 begin 为数组提供了一个特化版本,而模板对数组的型别推导在 Item 1 中已有讨论。
C++14 纠正了 C++11 的短视,添加了 cbegin、cend、rbegin、rend、crbegin、crend。
注意,在最通用的代码中,优先选用非成员函数版本的 begin、end、rbegin等,而非其成员函数版本。因为,最通用化的代码会使用非成员函数,而不假定其成员函数版本的存在性。
Item 14: Declare functions noexcept if they won’t emit exceptions
在 C++11 形成过程中,逐渐达成了一个共识,一个函数或者可能发生异常,或它保证自己不会。noexcept 就是为了不会发射异常的函数准备的,并且 noexcept 声明是函数接口的组成部分,事关接口设计,是客户方面关注的核心,调用方可能会对它有依赖。
对不会发射异常的函数应用 noexcept 声明可以让编译器生成更好的目标代码。在带有 noexcept 声明的函数中,优化器可能不需要在异常传出函数的前提下,将执行期栈保持在可开解状态(在 C++98 异常规格下,调用栈会开解至函数的调用方),也不需要在异常逸出函数的前提下,保证所有其中的对象以其被构造顺序的逆序完成析构。
noexcept 性质对于移动操作至关重要。在容器中,只有在保证移动操作不会产生异常时,才会使用移动,否则会使用复制。而一个函数(移动构造函数等)怎么能知道移动操作不会产生异常呢?答案是,通过校验看看容器内元素型别的移动操作是否带有 noexcept 声明。
swap 函数是许多 STL 算法实现的核心组件。标准库中的 swap 是否带有 noexcept 声明,取决于用户定义的 swap 是否带有 noexcept 声明。高阶数据结构的 swap 行为要 noexcept 性质,一般地,仅当构建它的低阶数据结构具备 noexcept 性质时才成立。例如标准库为数组和 std::pair 准备的 swap 函数使用带条件式 noexcept 声明,它们到底是不是具备 noexcept 性质,取决于它的 noexcept 分句中的表达式是否结果为 noexcept,即取决于数组和 std::pair 的元素型别的 swap 行为是否为 noexcept。
优化诚可贵,正确价更高。noexcept 乃是函数接口的组成部分,所以应该只在函数实现长期具有 noexcept 性质的前提下,才给予其 noexcept 声明。
在 C++11 中,默认地,内存释放函数(operator delete 或 operator delete[])和所有的析构函数(无论是用户定义的,还是编译器自动生成的)都隐式地具备 noexcept 性质。析构函数未隐式地具备 noexcept 性质的唯一场合,就是所在类中有数据成员(包括继承而来的成员,以及在其他数据成员中包含的数据成员)的型别显式地将其析构函数声明为可能发射异常的(即为其加上 “noexcept(false)” 声明)。
大多数函数都是异常中立的,不具备 noexcept 性质。由于有着确实的理由使得带有 noexcept 声明的函数依赖于缺乏 noexcept 保证的代码,C++ 允许此类代码通过编译,并且编译器通常不会就此生成警告。
Item 15: Use constexpr whenever possible
constexpr 对象都具备 const 属性,并由编译期已知的值完成初始化。
constexpr 函数在调用时若传入的是编译期常量,则产出编译期常量,若传入的是直至运行期才知晓的值,则产出运行期值。
- constexpr 函数用在要求编译期常量的语境(例如使用 constexpr 对象保存函数的返回结果)中时,传给一个 constexpr 函数的实参值是在编译期已知的,则结果也会在编译期计算出来。如果任何一个实参值在编译期为未知,则代码无法通过编译。
- 在不要求编译期常量的语境中调用 constexpr 函数时,传入的值有一个或多个在编译期未知,则它的运作方式和普通函数无异,即它也是在运行期执行结果的计算。这意味着,执行同样操作的函数,仅仅应用语境一个是要求编译期常量的,一个是用于所有其他值的话,那就不必写两个函数。constexpr 函数就可以同时满足所有需求。
constexpr 函数仅限于传入和返回字面型别(literal type),意思就是这样的型别(在 C++11 中,除了 void 的所有内建型别均符合)能够持有编译期可以决议的值。用户自定义的型别同样可以是字面型别,因为它的构造函数和其他成员函数可能也是 constexpr 函数。C++14 进一步放宽了 constexpr 的诸多使用限制。
只要有可能使用 constexpr,就使用它。比起非 constexpr 对象或 constexpr 函数而言,constexpr 对象或是 constexpr 函数可以用在一个作用域更广的语境中。也要注意,“只要有可能使用 constexpr,就使用它” 这句话中的 “只要有可能” 的含义就是你是否有一个长期的承诺,将由 constexpr 带来的种种限制施加于相关的函数和对象之上。
Item 16: Make const member functions thread safe
const 成员函数意味着它所代表的是一个读操作,多个线程在没有同步的条件下执行读操作是安全的,至少会被认为是安全的。因此,保证 const 成员函数的线程安全性,避免发生数据竞险(data race),除非可以确信它们不会用在并发语境中。
运用 std::atomic 型别的变量会比运用互斥量提供更好的性能,但前者只适用对单个变量或内存区域的操作。
Item 17: Understand special memeber function generation
C++11 中,支配 special member function 的机制如下:
- Default constructor:仅当类中不包含用户声明的构造函数时才生成。
- Destructor:析构函数默认为
noexcept,仅当基类的析构函数为虚的,生成的派生类的析构函数才是虚的。 - Copy-constructor:按成员进行非静态数据成员的复制构造。仅当类中不包含用户声明的复制构造函数时才生成。如果该类生成了移动操作,则复制构造函数将被删除。在已经存在复制赋值运算符或析构函数的条件下,仍然生成复制构造函数已经成为了被废弃的行为。
- Copy-assignment operator:按成员进行非静态数据成员的复制赋值。仅当类中不包含用户声明的复制赋值运算符时才生成。如果该类生成了移动操作,则复制赋值运算符将被删除(中文原文这儿写的是复制构造函数将被删除)。在已经存在复制构造函数或析构函数的条件下,仍然生成复制赋值运算符已经成为了被废弃的行为。
- Move-constructor/Move-assignment operator:都按成员进行非静态数据成员的移动操作。仅当类中不包含用户声明的复制操作、移动操作和析构函数时才生产。按成员移动由两部分组成,一部分是在支持移动操作的成员上执行的移动操作,另一部分是在不支持移动操作的成员上执行的复制操作。
C++11 可以通过 =default 显式地为这些操作生成编译器的默认行为。
成员函数模板在任何情况下都不会抑制特种成员函数的生成。哪怕,成员函数模板具现出的是这些操作中的某一个,也是如此。
Chapter 4. Smart Pointers
Item 18: Use std::unique_ptr for exclusive-ownership resource management
std::unique_ptr 是小巧、高速的、具备只移型别的智能指针,对托管资源实施专属所有权语义。一个非空的 std::unique_ptr 总是拥有其所指涉到的资源。移动一个 std::unique_ptr 会将所有权从源指针移至目标指针(源指针被置空)。std::unique_ptr 不允许复制,因为如果复制了一个 std::unique_ptr,就会得到两个指渉到同一资源的 std::unique_ptr,而这两者都认为自己拥有(因此应当析构)该资源。因而,std::unique_ptr 是个只移型别。
默认地,资源的析构是通过对 std::unique_ptr 内部的裸指针实施 delete 完成的。在使用默认析构器(即 delete 运算符)的前提下,可以合理地认为 std::unique_ptr 和裸指针尺寸相同。在析构过程中 std::unique_ptr 可以被设置成使用自定义析构器(custom deleter):析构资源时所调用的任意函数(或函数对象,包括那些由 lambda 表达式产生的)。若析构器是函数指针,那么 std::unique_ptr 的尺寸一般会增加一到两个字长(word),若析构器是函数对象,则带来的尺寸变化取决于该函数对象中存储了多少状态。无状态的函数对象(例如,无捕获的 lambda 表达式)不会浪费任何存储尺寸。所以,当这几种析构器都可用时,lambda 表达式是更好的选择。
std::unique_ptr 以两种形式提供,一种是单个对象(std::unique_ptr<T>),另一种是数组(std::unique_ptr<T[]>)。std::unique_ptr 的 API 也被设计成与使用形式相匹配。单个对象形式不提供索引运算符(operator []),而数组形式则不提供提领运算符(operator* 和 operator->)。作者说他唯一能想到 std::unique_ptr<T[]> 的合理使用场景是使用了一个 C 风格的 API,它返回了堆上的裸指针,且指定了其指渉对象的所有权。
工厂函数是 std::unique_ptr 的常用惯例。std::unique_ptr 可以方便高效地转换成 std::shared_ptr。工厂函数并不知道调用者是对其返回的对象采用专属所有权语义好,还是共享所有权更合适,std::unique_ptr 作为工厂函数的返回型别就向调用者提供了最高效的智能指针,且它也不会阻止调用者把返回值转换成更具弹性的其他兄弟型别的智能指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class Investment{
public:
...
virtual ~Investment(); // 必备的设计组件!
...
};
class Stock : public Investment { ... };
class Bond : public Investment { ... };
class RealEstate : public Investment { ... }; // 继承谱系
template<typename... Ts>
auto makeInvestment(Ts&&... params) // 工厂函数
{
auto delInvmt = [](Investment* pInvestment) // 一个作为自定义析构器的
{ // lambda 表达式
makeLogEntry(pInvestment);
delete pInvestment;
};
std::unique_ptr<Investment, decltype(delInvmt)>
pInv(nullptr, delInvmt); // 待返回的指针
if(...)
{
pInv.reset(new Stock(std::forward<Ts>(params)...));
}
else if(...)
{
pInv.reset(new Bond(std::forward<Ts>(params)...));
}
else if(...)
{
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}
std::shared_ptr<Investment> sp = // 将 std::unique_ptr 型别的对象
makeInvestment( arguments ); // 转换为 std::shared_ptr 型别
Item 19: Use std::shared_ptr for shared-ownership resource management
std::shared_ptr 提供方便的手段,实现了任意资源在共享所有权语义下进行生命周期管理的垃圾回收。所有指渉到对象的 std::shared_ptr 共同协作,确保在不再需要该对象的时刻将其析构。正如垃圾回收一样,用户无需操心如何管理被指涉到对象的生存期,但又如析构函数一样,该对象的析构函数的时序是确定的。std::shared_ptr 通过访问某资源的引用计数来确定自己是否是最后一个指渉到该资源的。引用计数是个与资源相关联的值,用来记录跟踪指渉到该资源的 std::shared_ptr 数量。引用计数的存在带来的一些性能影响:
- std::shared_ptr 的尺寸是裸指针的两倍。
- 引用计数的内存必须动态分配。
- 引用计数的递增和递减必须是原子操作,因为在不同的线程中可能存在并发的读写器。原子操作都比非原子操作慢。
std::shared_ptr 可以移动,移动操作会将源 std::shared_ptr 置空,一旦新的 std::shared_ptr 产生后,原有的 std::shared_ptr 将不再指渉到其资源,结果是不需要进行任何引用计数操作。因此,移动 std::shared_ptr 比复制它们要快:复制要求递增引用计数,而移动不需要。这一点对于构造和赋值操作同样成立。
std::shared_ptr 的自定义析构器设计比 std::unique_ptr 更具弹性:两个各有不同型别的自定义析构器的 std::shared_ptr<Widget> 由于本身具有具有同一型别,因此它们可以被放置在元素型别为该对象型别的容器中,也可以互相赋值,并且都可以被传递至要求 std::shared_ptr<Widget> 型别形参的函数。然而对于具有不同自定义析构型别的 std::unique_ptr 来说,以上这些均无法实现,因为自定义析构器的型别会影响 std::unique_ptr 的型别(前者是后者的一部分)。
1
2
3
4
5
std::unique_ptr<Widget, decktype(loggingDel)>> // 析构器型别是
upw(new Widget, loggingDel); // 智能指针型别的一部分
std::shared_ptr<Widget> // 析构器型别不是
spw(new Widget, loggingDel); // 智能指针型别的一部分
与 std::unique_ptr 的另一点不同,是自定义析构器不会改变 std::shared_ptr 的尺寸。自定义析构器可以是函数对象,而函数对象可以包含任意数量的数据(意味着它们的尺寸可能是任意大小),但是该部分内存不属于 std::shared_ptr 对象的一部分,它位于堆上,又或是 std::shared_ptr 的创建者利用了 std::shared_ptr 对自定义内存分配器的支持的话,则它会在托管给该分配器的内存位置。准确地说,每一个由 std::shared_ptr 管理的对象都有一个控制块。除了引用计数,该控制块还包含了自定义析构器和自定义内存分配器的一份复制(如果指定了的话),控制块还有可能包含其他附加数据:
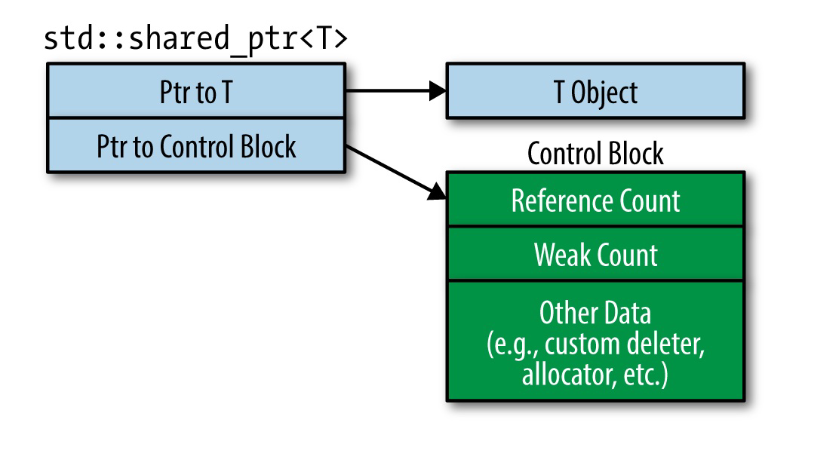
一个对象的控制块由创建首个指渉到该对象的 std::shared_ptr 的函数来确定。正在创建指渉到某对象的 std::shared_ptr 的函数是无从得知是否有其他的 std::shared_ptr 已经指渉到该对象的。因此,控制块的创建遵循了以下规则:
- std::make_shared 总是创建一个控制块。
- 从具备专属所有权的指针出发构造一个 std::shared_ptr 时,会创建一个控制块。
- 当 std::shared_ptr 构造函数使用裸指针作为实参来调用时,它会创建一个控制块。这样的话:从一个裸指针出发来构造不止一个 std::shared_ptr 的话,兼职如同免费搭乘了粒子加速器像未定义行为直奔而去。因此,尽可能避免将裸指针传递给一个 std::shared_ptr 的构造函数(使用 std::make_shared),如果必须将一个裸指针传递给 std::shared_ptr 的构造函数,就直接传递
new运算符的结果,而非传递一个裸指针变量。使用裸指针变量作为 std::shared_ptr 构造函数实参时,会有一种令人吃惊的方式导致涉及this指针的多重控制块。书上讲述了针对类似这种情况,std::shared_ptr 的 API 提供一种基础设施。
通常的控制块要更加复杂,使用了继承,甚至会用到虚函数(用以确保所指渉到的对象被适当地析构)。
一旦你将资源的生存期托管给了 std::shared_ptr ,就不能再更改注意了。即使引用计数为一,也不能回收该资源的所有权,并让一个 std::unique_ptr 来管理它。和 std::unique_ptr 的另一个不同是,std::shared_ptr 的 API 仅被设计用来处理指渉到单个对象的指针。并没有所谓的 std::shared_ptr<T[]>。另一方面,std::shared_ptr 支持从派生类到基类的指针型别转换,std::unique_ptr<T> 也支持,但 std::unique_ptr<T[]> 禁止此型别转换。
Item 20: Use std::weak_ptr for std::shared_ptr-like pointers that can dangle
std::weak_ptr 像 std::shared_ptr 那样运作,又无需参与管理所指渉到的对象的共享所有权(不影响其指渉对象的引用计数)。它通过跟踪指针何时空悬来判断其所指渉到的对象已不复存在,从而处理其所指渉到的对象有可能已被析构的问题。std::weak_ptr 不能提领,也不能检查是否为空,因为 std::weak_ptr 并不是一种独立的智能指针,而是 std::shared_ptr 的一种扩充。std::weak_ptr 一般是通过 std::shared_ptr 来创建的。
使用 std::weak_ptr 来代替可能空悬的 std::shared_ptr。std::weak_ptr 可能的用武之地包括缓存,观察者列表,以及避免 std::shared_ptr 指针环路。
std::weak_ptr 和 std::shared_ptr 的对象尺寸相同,它们和 std:: shared_ptr 使用同样的控制块,其构造,析构,赋值操作都包含了对引用计数的原子操作。std::weak_ptr 不干涉对象的共享所有权,不会影响所指渉到的对象的引用计数,实际上控制块里还有第二个引用计数,std::weak_ptr 操作的就是这第二个引用计数。
Item 21: Prefer std::make_unique and std::make_shared to direct use of new
三个 make 系列函数:std::make_unique,std::make_shared,std::allocate_shared。make 系列函数会把一个任意实参集合完美转发给动态分配内存的对象的构造函数,并返回一个指渉到该对象的智能指针。std::allocate_shared 的行为和 std::make_shared 一样,只不过它的第一个实参是个用以动态分配内存的分配器对象。
优先选用 make 系列函数的原因:
- 软件工程的一个重要原则:代码冗余应该避免。如下面的示例代码所示,使用 new 的版本将被创建对象的型别重复写了两遍,一次发生在声明智能指针对象型别时,另一次发生在 new 操作符后面指定 new 的对象型别。
- 第二个原因就是老生常谈的异常安全性。由于 C++ 对函数调用的实参求值顺序不作强制要求,进而容易因异常安全造成函数调用过程中新分配资源的泄露。
- 性能提升:std::make_shared 会让编译器有机会利用更简洁的数据结构产生更小更快的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
processWidget(std::shared_ptr<Widget>(new Widget), // 潜在的
computePriority()); // 资源泄露
processWidget(std::make_shared<Widget>(), // 不会发生潜在的资源泄露
computePriority()):)
// 引发两次内存分配:
// 1. new 为 Widget 进行一次内存分配
// 2. std::shared_ptr 的构造函数分配控制块的内存
std::shared_ptr<Widget> spw(new Widget);
// 一次内存分配足矣:
// std::make_shared 分配单块内存
// 即保存 Widget 对象又保存与其相关联的控制块
auto spw = std::make_shared<widget>();
上面提到的优化减小了程序的静态尺寸,因为代码只包含一次内存分配调用,同时还增加了可执行代码的运行速度,因为内存是一次性分配出来的。
一些不能或者不应该使用 make 系列函数的情景:
- 所有的 make 系列函数都不允许使用自定义析构器。
- make 系列函数会向对象的构造函数完美转发其形参,对形参进行完美转发的代码使用的是圆括号而给大括号。假如需要使用大括号初始化物来创建指渉到对象的指针,就必须直接使用 new 表达式了。但也有变通做法:使用 auto 型别推导,从大括号初始化物出发,创建一个 std::initializer_list 对象,然后将 auto 创建的对象传递给 make 系列函数。
- 对于 std::shared_ptr,不建议使用 make 系列函数的额外场景包括:1. 自定义内存管理的类;2. 内存紧张的系统、非常大的对象、以及存在比指渉到相同对象的 std::shared_ptr 生存期更久的 std::weak_ptr。前面提到的优选 make 系列函数的原因中有个性能优势的原因,这源于 std::make_shared 的控制块和托管对象在同一内存块上分配。当对象的引用计数变为零时,对象被析构。然而,托管对象所占用的内存直到与其关联的控制块也被析构时才会被释放,因为同一动态内分配的存溶蚀包含了两者。控制块还包含着第二个引用计数,被称作弱计数。std::weak_ptr 通过检查控制块里的引用计数(而非弱计数)来校验自己是否失效。由于 std::weak_ptr 会指渉到某个控制块(即,弱计数大于零时),该控制块肯定会持续存在,包含它的内存肯定也会持续存在。
一旦发现自己处在一个不能够或者不适合使用 std::make_shared 的境地,就要确保之前见过的异常安全问题。最好的办法就是确保在一条语句里且不做其他任何事经 new 表达式的结果传递给智能指针的构造函数,以阻止编译器在 new 表达式的评估求值和调用智能指针的构造函数并接管 new 表达式产生的对象这个过程之间放出异常来。之后即使在智能指针的构造函数产生异常,也不会发生问题。
Item 22: When using the Pimpl Idiom, define special member functions in the implementation file
Pimpl (pointer to implementation) Idiom:把某类的数据成员用一个指渉到某实现类(或结构体)的指针替代,尔后把原来在主类中的数据成员放置到实现类中,并通过指针间接访问这些数据成员。Pimpl Idiom 降低类的客户和类实现者之间的依赖性,减少了构建次数。
Pimpl Idiom 的第一部分,是声明一个指针型别的数据成员,指渉到一个非完整型别,第二部分是通过动态分配和回收持有从前在原始类里的那些数据成员的对象,而分配和回收代码则放在实现文件中。
std::unique_ptr 可以支持非完整型别,Pimpl Idiom 是 std::unique_ptr 最广泛应用的场景之一。但使用 std::unique_ptr 实现 Pimpl Idiom 却不像看起来那么顺风顺水。
原因是,在使用了 std::unique_ptr 的类里,若未声明析构函数(因为显而易见不需要,编译器会为我们生成),也就无需为其撰写代码,而编译器为我们生成析构函数,并在其内插入代码来调用类中的数据成员 pImpl(一个指渉到非完整型别的 std::unique_ptr),pImpl 的默认析构器在 std::unique_ptr 内部使用 delete 运算符来针对裸指针实施析构。在实施 delete 运算符之前,C++11 中的 static_assert 要去确保裸指针未指渉到非完整型别。这样一来,当编译器为带有指渉非完整型别的 std::unique_ptr 的类的析构函数产生代码时,通常就会遇到一个失败的 static_assert,从而导致错误信息的产生。这个错误信息和该类被析构的位置(例如,离开作用域)有关,那一刻析构函数被调用,而特种成员函数基本上是隐式 inline 的。
解决上面这个问题很简单:保证在生成析构代码处, pImpl 指向的型别完整即可,只要型别的定义可以被看到,它就是完整的。因此,成功编译的关键在于让编译器看到析构函数的函数体的位置在实现文件内部的未完整型别的定义之后。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class Widget{ // 位于头文件 “widget.h” 内
public:
Widget();
~Widget(); // 仅声明!
Widget(Widget&& rhs); // 仅声明!
Widget& operator=(Widget&& rhs); // 仅声明!
Widget(const Widget& rhs); // 仅声明!
Widget& operator=(const Widget& rhs);
...
private:
struct Impl; // 声明实现结构体
std::unique_ptr<Impl> pImpl; // 以及指渉到它的智能指针
};
#include "widget.h" // 位于实现文件 “widget.cpp” 内
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // Widget::Impl 的实现
std::string name; // 包括本在 Widget 中的数据成员
std::vector<double> data;
Gadget g1, g2, g3; // Gadget 是某种用户自定义型别
};
Widget::Widget() : pImpl(std::make_unique<Impl>()) {}
// ~Widget 的定义放在 Widget::Impl 定义之后
// 编译器在这儿生成代码,析构时 Widget::Impl 是个完整型别了
Widget::~Widget() = default;
Widget::Widget(Widget&& rhs) = default; // 在这里放置定义
Widget& Widget::operator=(Widget&& rhs) = default; // 理由类似
Widget::Widget(const Widget& rhs)
: pImpl(std::make_unique<Impl>(*rhs.pImpl))
{}
Widget& Widget::operator=(const Widget& rhs)
{
*pImpl = *rhs.pImpl;
return *this;
}
在 Widget 中声明析构函数的举动会阻止编译器产生移动操作。需要支持移动操作就必须自己声明,而编译器生成的移动赋值操作需要在重新赋值前析构 pImpl 指渉到的对象,并且编译器会在移动构造函数内抛出异常的事件中,生成析构 pImpl 的代码。前面说过,对 pImpl 析构要求 Impl 具备完整型别。因此,如上面代码所示,移动操作的处理手法是如法炮制,移动操作的定义被移入实现文件里了。
Pimpl Idiom 是一种可以在类实现和类使用者之间减少编译依赖性的方法,但从概念上说,Pimpl Idiom 并不能改变类所代表的事物。编译器不会为像 std::unique_ptr 这样的只移型别生成复制操作,即使编译器可以生成,其生成的函数也只能实施浅复制,而我们希望的则是深复制。上面利用了编译器为 Impl 类创建的复制操作会自动逐项复制这些字段的特性,采用 Widget::Impl 的编译器生成的复制操作实现了 Widget 的复制操作。
值得指出的是,如果我们在这里使用 std::shared_ptr 而非 std::unique_ptr 来实现 pImpl,则本条款的建议不再适用,无需在 Widget 中声明析构函数,编译器乐意生成的特殊成员函数会精确地按我们想要的方式运作。两者的不同源自它们对于自定义析构器的支持的不同。std::unique_ptr 的析构器型别是智能指针型别的一部分,析构器型别在编译期已知,这使得编译器会产生更小尺寸的运行期数据结构以及更快速的运行期代码。而如此高效带来的后果就是欲使用编译器生成的特种函数,就要求其指渉到的型别必须是完整型别。std::shared_ptr 的析构器型别并非智能指针型别的一部分,这就需要更大尺寸的运行时期数据结构以及更慢一些的目标代码,但在使用编译器生成的特种函数时,并不要求其指渉到的型别是完整型别。
就 Pimpl Idiom 而言,在专属所有权的情景下,std::unique_ptr 是完成任务的合适工具。而在共享所有权的情景下,std::shared_ptr 成为合适的设计选项,就大可不必忍受 std::unique_ptr 所带来的必须自行撰写一系列函数定义的煎熬。
Chapter 5. Rvalue References, Move Semantics, and Perfect Forwarding
Item 23: Understand std::move and std::forward
std::move 并不进行任何移动,std::forward 也不进行任何转发,函数的行为与其字面意义不符,这两者在运行期都无所作为,它们不会生成任何可执行代码,连一个字节都不会生成。std::move 和 std::forward 都是仅仅执行强制型别转换的函数(其实是函数模板)。std::move 无条件地将实参强制转换成右值:
1
2
3
4
5
6
template<typename T>
decltype(auto) move(T&& param)
{
using ReturnType = remove_reference_t<T>&&;
return static_cast<ReturnType>(param);
}
std::move 的形参是指渉到一个对象的万能引用,返回的是指渉到同一个对象的右值引用。它将型别特征(参见 Item 9)std::remove_reference_t 应用于 T,从而保证 “&&” 应用在一个非引用型别之上(如果 T 是个左值引用,T&& 就成了左值引用),确保 std::move 返回的是右值引用。这就是该函数的全部作为,强制型别转换,而不是移动。当然,右值是可以移动的,所以在一个对象上实施了 std::move,就是告诉编译器该对象具备可移动的条件。这就是 std::move 得名的原因:它简化了对象是否可移动的表述。
指渉到常量的左值引用(const T& rhs)允许绑定到一个常量右值型别的形参(const T&&)。因此,对常量对象执行移动操作将一声不响地变换成复制操作。语言不允许常量对象传递到有可能改动它们的函数(例如移动构造函数,移动构造函数值能接受非常量型别的右值引用作为形参,而复制操作的形参一般是指渉到常量的左值引用,可以绑定到一个常量右值型别)。如果想取得对某个对象执行移动操作的能力,则不要将其声明为常量,因为针对常量对象执行的移动操作将变换成复制操作;其次,std::move 不仅不实际移动任何东西,甚至不保证经过其强制型别转换后的对象具备可移动能力。关于针对任意对象实施过 std::move 的结果,为一个可以确定的是,该结果会是个右值。
std::forward 是一个有条件强制型别转换。其典型使用场景:某个函数模板取用了万能引用型别为形参,随后将其传递给另一个函数,而所有函数形参皆为左值,另一个函数的调用都会是取用了左值型别的那个重载版本。std::forward 的有条件强制型别转换:仅当其实参是使用右值完成初始化时,它才会执行向右值型别的强制型别转换。实参的初始化信息通过模板形参 T 传递给 std::forward。
std::move 只取用一个函数实参,而 std::forward 则即需取用一个函数实参,又需取用一个模板型别实参(T)。使用 std::move 所要传达的意思是无条件地向右值型别的强制转换,而使用 std::forward 则想说明仅仅对绑定到右值的引用(是个左值)实施像右值型别的强制型别转换。前者是典型地为移动操作做铺垫,而后者仅仅是传递(转发)一个对象到另一个函数,而在此过程中无论该对象原始型别具备左值性(lvalueness)和右值性(rvalueness),都保持原样。
Item 24: Distinguish universal references from rvalue references
如果函数模板形参具备 T&& 型别,并且 T 的型别系推导而来,或如果使用 auto&& 声明其型别,则该形参或对象就是个万能引用。如前所述,万能引用在两种场景下现身:函数模板的形参和 auto 声明。这两个场景的共同之处,在于它们都涉及型别推导。万能引用涉及型别推导,且其形式必须得正好形如 “T&&” 才行(但没必要一定要取 “T” 这个名字)。也要注意,“位于模板内“ 且形如 “T&&” 并不能保证 “一定涉及型别推导”。
如果型别声明并不精确地具备 type&& 的形式,或者型别推导并未发生,则 type&& 就代表右值引用。它们仅仅会绑定到右值,其主要存在理由就是识别出可移对象。
引用的初始化是必需的。若采用右值来初始化万能引用,就会得到一个右值引用。若采用左值来初始化万能引用,就会得到一个左值引用。
Item 25: Use std::move on rvalue references, std::forward on universal references
当转发右值引用给其他函数时,应当对其实施向右值的无条件强制型别转换(通过 std::move),因为它们一定绑定到右值;而当转发万能引用时,应当对其实施向右值的有条件强制型别转换(通过 std::forward),因为它们不一定绑定到右值。
若用一对通过左值和右值引用的重载函数来替换使用万能引用形参的函数模板,很可能在某些情况下引发运行期效率问题。依左值和右值的重载的最严重问题并不是代码膨胀或者对习惯用法的背离,甚至也不是运行期的效率折损,而是这种设计的可扩展性太差。对于那些有多个形参的函数,每个形参都需要一个左值和右值,从而重载函数的个数会呈几何级数增长:有 n 个形参,就需要 2^n 个重载函数。类似 std::make_shared 和 std::make_unique,这样的函数模板有无穷多个形参,而每个形参都可能是左值或是右值。对于这样的函数,针对左值和右值进行重载并不可行,万能引用才是唯一的解决之道。保证在这些函数内部,当万能引用的形参被传递给其他函数时,针对它们实施 std::forward。在单一函数内,为保证在完成针对这两种引用对象的其他所有操作完成之前,其值不被移走,仅在最后一次使用这两种引用时,才对其实施 std::move(右值引用)或 std::forward(万能引用)。
在按值返回的函数中,如果返回的是绑定到一个右值引用或一个万能引用的对象,则当你返回该引用时,应该对其实施 std::move 或者 std::forward。这样做是因为,一个右值的值会被移入函数的返回值存储位置,而一个左值会强迫编译器将其复制入返回值存储位置。假如返回值不支持移动操作,也并无大碍,右值也会通过复制操作完成复制入返回值存储位置。如果返回值型别够面又被修改为支持移动操作,则下次编译完成后 就能自动获益了。
上面的优化似乎可以用于欲返回的局部变量(注意与上面的不同)上。是的,但标准化委员会领先的返回值优化(return value optimization, RVO)更好:直接在为函数返回值分配的内存上创建局部变量来避免复制之。编译器若要在一个按值返回的函数里省略对局部对象的复制(或者移动),则需满足两个前提条件:1.局部对象型别和函数返回值型别相同;2.返回的就是局部对象本身(非对局部对象的引用)。即使实施 RVO 的前提条件未满足,编译器选择不执行复制省略的时候,返回对象也必将被作为右值处理。也就是标准要求:当 RVO 的前提条件允许时,要么发生复制省略,要么 std::move 隐式地被实施于返回的局部对象之上。若局部对象可能适用于返回值优化(不执行复制省略,就必须将局部对象作为右值处理),则请勿针对其实施 std::move 或 std::forward(可能会排除掉 RVO 复制省略的机会)。
Item 26: Avoid overloading on universal references
形参为万能引用的函数避免了代码臃肿,同时带来了效率的提升。种种好处都是源于它是 C++ 中最贪婪的:它们会在具现过程中,和几乎任何实参型别产生精确匹配。这就是为何把重载和万能引用这两者结合起来几乎总是馊主意:一旦万能引用成为重载候选,它就会吸引走大批的实参型别,远比撰写重载代码的程序员期望的要多。
完美转发构造函数的问题尤为严重,因为对于非常量的左值型别而言,它们一般都会形成相对于复制构造函数的更佳匹配,并且它们还会劫持派生类中对基类的复制和移动构造函数的调用。并且完美转发的构造函数模板并不能阻止编译器生成默认复制和移动构造函数来。
尽可能避免把万能引用型别作为重载函数的形参选项。若需针对绝大多数的实参型别实施转发,只针对某些实参型别实施特殊处理,这时该怎么做呢?解决之道在下一条款。
Item 27: Familiarize yourself with alternatives to overloading on universal references
依万能引用型别进行重载会导致形形色色的问题,独立函数和成员函数(构造函数尤其问题严重)。一些可行的设计的手法:
- 舍弃重载:对于个别函数只需要把本来打算进行重载的版本重新命名成不同的U盾讴歌名字就可以避免以万能引用型别进行重载。许多情况(比如构造函数)都不适用这种方法,而且彻底放弃重载也不是长久之计呀!
- 使用传递左值常量引用型别来代替传递万能引用型别。缺点就是达不到我们想要的高效率,不过有时候保持简洁性不失为有一定吸引力的权衡结果。
- 遵循 Item 41 的建议 —— 当你知道肯定需要赋值形参时,考虑按值传递对象。即把传递的形参从引用型别替换成值型别。
- 标签分派:一不想放弃重载,二不想放弃万能引用。一个万能引用形参通常会导致的后果是无论传入了什么都给出一个精确匹配结果。如果万能引用仅是形参列表的一部分,该列表还有其他非万能引用型别的形参的话,那么只要该非万能引用型别形参具备充分差的匹配能力,则它就足以决定这个带有万能引用形参的重载版本是否出局:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
std::multiset<std::string> names; // 全局数据结构
template<typename T>
void logAndAdd(T&& name)
{
logAndAddImpl(
std::forward<T>(name),
std::is_integral<std::remove_reference_t<T>>()
)
}
template<typename T>
void logAndAddImpl(T&& name, std::false_type)// 非整形实参,
{ // 将名字添加到全局数据结构中
auto now = std::chrono::system_clock::now();
log(now, logAndAdd);
names.emplace(std::forward<T>(name));
}
std::string nameFromIdx(int idx);
void logAndAddImpl(int idx, std::true_type) // 整形实参,
{ // 查找名词并用它调用
logAndAdd(nameFromIdx(idx)); // logAndAdd
}
在上述设计中,型别 std::false_type 和 std::true_type 即使所谓 “标签”,运用它们的唯一目的在于强制重载决议按我们想要的方向推进。这就能将万能引用和重载加以组合却不会引发条款 26 所描述的问题。存在一个单版本(无重载版本的)函数作为客户端 API(logAndAdd),该单版本会把待完成的工作分派到实现函数。实现函数 logAndAddImpe 实施了重载,每个重载版本都接受一个万能引用实参,但重载决议却并不仅对这个万能引用形参有依赖,还对标签有依赖,而标签值又加以设计以保证可以命中匹配的函数不会超过一个。这样设计的结果是,只有标签值才决定了调用的是哪个重载版本。
- 对接受万能引用的模板施加限制。关于类的完美转发构造函数,编译器可能自行生成复制和移动构造函数,在一个构造函数中运用标签分派手法,编译器可能让其他构造函数处理构造,从而绕过标签分派系统。条款 26 说过,提供了一个接受万能引用形参的构造函数会导致复制非常量左值时总会调用到该万能引用构造函数(而非复制构造函数)。且派生类以传统方式实现其复制和移动构造函数时,总会调用到基类中声明的完美转发构造函数。也就是,接受了万能引用形参的重载函数并未贪婪到能够独当一面成为单版本分配函数的程。
std::enable_if可以砍掉含万能引用函数模板被允许采用的一部分条件。实施了std::enable_if的模板只会在满足了std::enable_if指定的条件的前提下才会启用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Person{
public:
template< typename T,
typename = std::enable_if_t<
!std::is_base_of<Person,std::decay_t<T>>::value
&&
!std::is_integral<std::remove_reference_t<T>>::value
>
>
explicit Person(T&& n) // 接受 std::string 型别以及
: name(std::forward<T>(n)) // 可以强制转型到 std::string 的实参型别的
{ ... } // 构造函数
explicit Person(int idx) // 接受整形实参的构造函数
: name(nameFromIdx(idx)) // 上面的函数模板被限制了整形实参
{ ... }
... // 复制和移动构造函数等,接受 Person 或继承自 Person 的型别
private:
std::string name;
}
std::decay<T>::type 和 T 相同,区别在于它移除了 T 的引用和 cv 饰词(即 const 或 volatile 饰词),也用于把数组和函数型别强制转型成指针型别。std::is_base_of<T1, T2>::value,若 T2 是由 T1 派生而来时,其值为真。所有型别都可以认为是从它自身派生而来,所以 std::is_base_of<T, T>::value 是 “真”。因此,上面的 std::enable_if_t<condition> 的条件是传递给完美转发构造函数的型别不是 Person 或继承自 Person 的型别并且也不是整形,是的话模板禁用之,只有条件满足时,函数模板才会被启用。
头三种技术(舍弃重载、传递 const T& 型别的形参和传值)都需要对待调用的函数形参逐一指定型别,而后两种技术(标签分派和对模板的启用资格施加限制)则利用了完美转发,无须指定形参型别。完美转发效率更高,因为它出于和形参声明时的型别严格保持一致的目的,会避免创建临时对象。但是针对某些型别无法实施完美转发,尽管它们可以被传递到接受特定型别的函数(Item 30)。当客户在传递了非法形参时,万能引用的转发次数越多,某些地方给出的错误信息就越让人摸不着头脑。
Item 28: Understand reference collapsing
1
2
template<typename T>
void func(T&& param);
若实参被用以初始化的形参为万能引用,实参在传递给函数模板时,推导出来的模板形参会将实参是左值还是右值的信息编码到结果型别中。编码机制:如果传递的实参是个左值,T 的推导结果就是个左值引用型别;如果传递的实参是个右值,T 的推导结果就是个非引用型别(注意这里的非对称性,左值的编码结果为左值引用型别,但右值的编码结果却是非引用型别)。注意,这儿仅说的是 T 的推导结果,而非 param 的型别。
在 C++ 中,“引用的引用” 是非法的。但编译器却可以在特殊的语境中产生引用的引用,引用折叠机制将支配这一过程,双重引用会折叠成单个引用:如果任一引用为左值引用,则结果为左值引用,否则(即两个皆为右值引用)结果为右值引用。
引用折叠会出现在四种语境中。第一种最常见的就是模板实例化:
1
2
3
4
5
6
7
8
9
10
11
12
template<typename T>
void f(T&& fParam)
{
...
someFunc(std::forward<T>(fParam));
}
template<typename T> // C++14
T&& forward(remove_reference_t<T>& param) // 仍在名字空间 std 中
{
return static_cast<T&&>(param);
}
上面是 std::forward 的一种能够完成任务的实现。假设传递给函数 f 的实参的型别是个左值 Widget,则 T 会被推导为 Widget& 型别,然后对 std::forward 的调用就会实例化 std::forward<Widget&>,造成的结果是:接受一个左值引用,并返回一个左值引用。而 std::forward 内部的强制型别转换未做任何事情。假设传递给 f 的实参是右值 Widget 型别,T 的推导结果是个光秃秃的 Widget。因此,f 内部的 std::forward 就成了 std::forward<Widget>,函数返回右值引用,std::forward 把 f 的形参 fParam 转换成右值。注意,上面的两个形参 fParam 和 param 任何情况下都是左值。
引用折叠的其他三种语境:auto 变量的型别生成(和模板实例化一模一样)、创建和运用 typedef 和别名声明、decltype 的运用(如果在分析一个涉及 decltype 的型别过程中出现了引用的引用,则引用折叠会介入并消灭之)。
万能引用相当于满足下面两个条件的语境中的右值引用:
- 型别推导的过程会区分左值和右值。T 型别的左值推导结果为 T&,而 T 型别的右值则推导结果为 T。
- 会发生引用折叠。
Item 29: Assume that move operations are not present, not cheap, and not used
假定移动操作不存在、成本高、未使用。
对于那些型别或对于移动语义的支持情况已知的代码,则无需作以上假定。
Item 30: Familiarize yourself with perfect forwarding failure cases
“转发” 的含义是一个函数把自己的形参传递(转发)给另一个函数,其目的是为了让第二个函数(转发目的函数)接受第一个函数(转发发起函数)所接受的同一对象。这就排除了按值传递形参,因为它们只是原始调用者所传递之物的副本。我们想要转发目的函数能够处理原始传入对象,同时不想强迫调用者传递指针,指针形参也只能出局。论及一般意义上的转发时,都是在处理形参为引用型别的情形。“完美转发” 的含义是不仅转发对象,还转发其显著特征:型别、左右值性,以及是否带有 cv 饰词等。因此,我们运用万能引用,因为只有万能引用形参才会将传入的实参是左值还是右值这一信息编码。转发函数天然就应该是泛型的,一种符合逻辑的扩展就是使得转发1函数不只是模板,而且是可变长形参模板,从而能够接受任意数量的实参。
给定目标函数 f 和转发函数 fwd,当以某特定实参调用 f 会执行某操作,而用同一实参调用 fwd 会执行不同的操作,则称完美转发失败,尽管后者确实是将实参完美转发给前者处理的。完美转发的失败情形,是源于模板型别推导失败,或推导结果是错误的型别。不能实施完美转发的实参:
- 大括号初始化物。向未声明为
std::initializer_list型别的函数模板形参传递大括号初始化物是 “非推导语境”,编译器禁止在这种函数模板的调用过程中从大括号初始化物出发来推导型别。 0和NULL用作空指针。- 仅有声明的 整形 static const 成员变量。这东西不需要给出定义,因为编译器会自根据这些成员的值实施常数传播,所以不必为它们保留内存。但是,引用这东西通常是当指针处理的,按引用传递整形 static const 成员变量通常要求其加以定义,而这个需求就会导致代码完美转发失败而等价的、未使用完美转发的代码却能成功。
- 重载的函数名字和模板名字。这玩意作为实参,意思就是实参是函数和模板。对于函数,在入口型别推导的时候就完全不知道后面要转发的是哪个重载版本呀;对于函数模板,也不知道是其具现化的哪个实例呀。这儿说的名字,而非型别。要想实施完美转发的函数接受重载函数名字或者模板名字,只有手动指定需要转发的哪个重载版本(其具体型别)或者实例(其具体型别)。完美转发函数一般用来设计接受任何型别的,若告知你要传递的具体型别,那还需要完美转发吗?
- 位域。位域是由机器字的若干任意部分组成的(例如,32 位 int 的第 3 到第 5 个比特),这样的实体不可能有办法对其直接取址,即没有办法把引用绑定到任意比特。但 C++ 规定的却是非 const 引用不得绑定到位域。这是因为,标准要求常量引用实际绑定到是存储在某标准整形中的位域值的副本。利用转发目的函数接受的总是位域值的副本这一事实,可以自己制作一个副本调用转发函数。
以上就是完美转发的不完美之处,了解如何规避它们。
Chapter 6. Lambda Expressions
lambda 式常用于创建闭包(运行期对象),闭包类就是实例化闭包的类。
Item 31: Avoid default capture modes
C++11 中有两种默认捕获模式:按引用或按值。按引用的默认捕获模式可能导致空悬引用,按值的捕获则并非是能避免空悬的好方法。按值捕获了一个指针以后,在 lambda 式创建的闭包中持有的是这个指针的副本,并无办法阻止 lambda 式之外的代码去针对该指针实施 delete 操作所导致的指针副本空悬。智能指针或许有用,但有时候裸指针就在我们眼皮底下实施 delete 操作,只不过现代 C++ 编程风格的源代码中经常难见其踪。一个裸指针隐式应用 —— this,每个一个非静态成员函数都持有一个 this 指针,然后每当提及该类的成员变量时都会用到这个指针。若在非静态成员函数中有个按值默认捕获的 lambda 式,则该 lambda 式捕获了 this 指针,从而可以使用成员变量(如同成员函数一样隐式地通过 this 指针)。同时 lambda 闭包的存活与这个 this 指针的对象的生命期是绑在一起的。若这个 this 指针所代表的对象被回收了,lambda 闭包中的 this 指针副本也就空悬了。
在 C++14 中,捕获成员变量的一种更好的方法是使用广义 lambda 捕获(generalized lambda capture):
1
2
3
4
5
6
7
void Widget::addFilter() const
{// filters 是全局数据结构,divisor 是 Widget 的成员变量,略掉了
filters.emplace_back( // C++14
[divisor = divisor](int value) // 将 divisor 复制入闭包
{ return value % divisor == 0; } // 使用副本
)
}
lambda 式可能不仅依赖于局部变量和形参(它们可以被捕获),还会依赖于静态存储期对象(这样的对象定义在全局或名字空间作用域中,又或在类中、在函数中、在文件中以 static 饰词声明,它们可以在 lambda 内使用,但是它们不能被捕获)。使用了按默认值捕获模式,就会给人以错觉,认为这些对象可以加以捕获,从而造成误认为 lambda 式是自洽的,但是其实在外部这些 “捕获” 的静态对象能够被修改,也可能会被改变,也就无自洽一说了。
Item 32: Use init capture to move objects into closures
使用 C++14 的初始化捕获(init capture),有机会指定:
- 由 lambda 生成的闭包类中的成员变量的名字。
- 一个表达式,用以初始化该成员变量。
初始化捕获使用 “=”。“=” 左侧的是你所指定的闭包类成员变量的名字,而位于其右侧的则是其初始化表达式。“=” 的左右两侧处于不同的作用域,左侧作用域就是闭包类的作用域,右侧的作用域则与 lambda 式加以定义之处的作用域相同。
在 C++11 中,可以经由手工实现的类或 std::bind 去模拟初始化捕获。
C++11 中,按移动捕获采用的模拟方法:
1.把需要捕获的对象移动到 std::bind 产生的函数对象(绑定对象)中。
2.给到 lambda 式一个指渉到欲 “捕获” 的对象的引用。
绑定对象(func2)存储着传递给 std::bind 所有 实参的副本,其中 data 在绑定对象中实施移动构造得到了一个副本,还有一份由 std::bind 的第一个实参的 lambda 式产生的闭包的副本。所以,该闭包的生命期和其引用的的绑定对象内移动构造而得的 data 副本是相同的:
1
2
3
4
5
6
7
8
9
10
std::vector<double> data; // 欲移入闭包的对象
...
auto func1 = [data = std::move(data)] // C++14 的初始化捕获
{/* 对数据加以运用 */ };
auto func2 = std::bind( // C++11 中
[](std::vector<double>& data) mutable //模拟初始化捕获的部分
{/* 对数据加以运用 */ },
std::move(data)
);
另一个在闭包内创建 std::unique_ptr 的例子:
1
2
3
4
5
6
7
8
9
10
auto func1 = [pw = std::make_unique<Widget>()]
{ return pw->isValidated()
&& pw->isArchived(); };
auto func2 = std::bind(
[](const std::unique_ptr<Widget>& pw)
{ return pw->isValidated()
&& pw->isArchived();},
std::make_unique<Widget>()
);
默认情况下,lambda 生成的闭包类中的 operator() 成员函数会带有 const 饰词,闭包里的所有成员变量在 lambda 式的函数体内都会带有 const 饰词。但是,绑定对象里移动构造得到的 data 副本却并不带有 const 饰词。为防止副本在 lambda 式内被意外修改,lambda 的形参就声明为常量引用(上面第二个例子)。lambda 式声明带有 multable 饰词时,闭包里的 operator() 函数就不会在声明时带有 const 饰词(上面第一个例子)。
Item 33: Use decltype on auto&& parameters to std::forward them
C++14 的泛型 lambda 式(generic lambda):lambda 可以在形参规格中使用 auto,同时能够接受可变长形参。这个特性的实现:闭包类中的 operator() 采用模板实现。
若 lambda 式的形参是个 auto&& 型别,在 lambda 内部需完美转发,但是 std::forward<T> 需要接受一个形参型别 T 。在泛型 lambda 式中,却没有可用的形参型别 T。decltype 提供了一种实现途径。先来熟悉下一些概念,左值传递给万能引用的形参,该形参型别会成为左值引用,传递右值,该形参会成为右值引用。因此,可以通过探查形参的型别,来判断传入的实参是左值还是右值。如果传入的是个左值,decltype(x) 将会产生左值引用型别,如果传入的是个右值,decltype(x) 将会产生右值引用型别。而 std::forward 的惯例是:用型别形参为左值引用表明想要返回左值,而用非引用型别时来表示想要返回的右值。对于 lambda 式,auto&& 型别的形参 x 绑定了左值,则 decltype(x) 将产生左值引用型别,转发也将返回左值,这没问题。不过,若 auto&& 型别的形参 x 绑定了右值,decltype(x) 将会产生右值引用,而非符合惯例的非引用型别。但是,实例化 std::forward 时,使用一个右值引用型别和使用一个非引用型别,会产生相同结果。所以,无论左值还是右值,把 decltype(x) 传递给 std::forward 都能给出想要的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
auto f =
[] (auto&& param)
{
return
func(normalize(std::forward<decltype(param)>(param)));
};
auto f =
[](auto&&... params) // 可变长形参
{
return
func(normalize(std::forward<decltype(params)>(params)...))
};
Item 34: Prefer lambdas to std::bind
lambda 式比起使用 std::bind 而言,可读性更好、表达力更强,可能运行效率更高。在 C++11 中,std::bind 在实现移动捕获,或是绑定到具备模板化的函数调用运算符的对象这两个场合,尚有余热发挥。但在 C++14 的 lambda 逐渐完善之后,std::bind 已经彻底失去了用武之地。